
データ活用が当たり前になった現在、AWSにはさまざまなデータ分析サービスが用意されています。その中でもAWS Glueは、分析前のデータを整えるために欠かせない存在です。
本記事では、AWS Glueの基本的な仕組みから特徴、料金、実際の使い方までを初心者向けに整理して解説します。データ分析基盤をこれから構築したい方は、ぜひ参考にしてください。
AWS Glueとは?
AWS Glueは、データ分析や活用の前段階となるETL処理を自動化・効率化するサーバーレス型のデータ統合サービスです。ここではGlueの仕組みについて解説します。
AWS GlueはETL(抽出・変換・ロードを行う)サービス
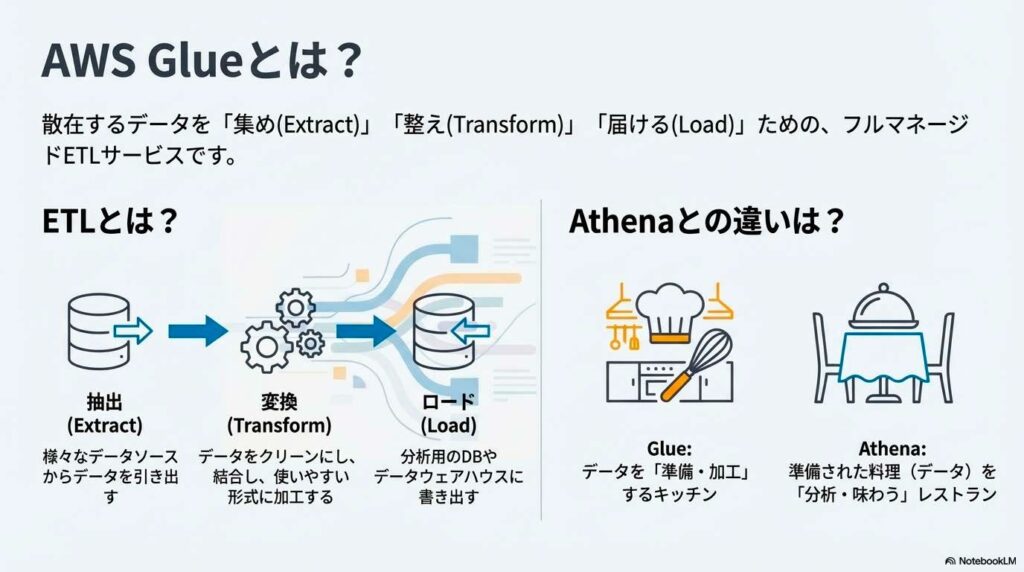
AWS Glueは、ETL(Extract・Transform・Load)処理を実行するためのフルマネージドサービスです。S3やRDS、DynamoDBなどのデータソースからデータを抽出し、形式変換やクレンジングなどの変換処理を行い、分析しやすい形で保存先にロードします。インフラの管理は不要で、ジョブは必要なときに自動で実行されます。
また、Glue Data Catalogによってテーブル定義やスキーマを一元管理でき、AthenaやRedshiftなど他のAWS分析サービスと連携しやすい点も特徴です。
Athenaとの違いは?
Glue はデータを「準備」するサービス
Athena はデータを「分析(クエリ)」するサービス
AWS GlueとAmazon Athenaは役割が明確に分かれています。Glueは、データを分析可能な状態に整える「データ準備」を担当するサービスです。一方、Athenaは、S3上のデータに対してSQLを実行する「データ分析(クエリ)」専用のサービスです。
Glueでスキーマ定義や形式変換を行い、Athenaでそのデータをクエリすることで、効率的な分析環境を構築できます。つまり、Glueが前処理、Athenaが分析という関係になります。
Amazon Athenaについて詳しく知りたい方はこちらの記事を参照してください。
Amazon Athenaとは?仕組み・料金・使い方を初心者向けにわかりやすく解説
AWS Glue の特徴
AWS Glueはさまざまなデータソースに接続できる点や、機械学習を活用した FindMatches 機能によるデータの名寄せにも対応してます。ここでは主要な特徴について紹介します。
1. サーバーレスと高い拡張性
インフラの構築やサーバー管理を行う必要がなく、処理実行時に自動でリソースが割り当てられます。データ量や処理内容に応じてDPU(Data Processing Unit)が動的にスケールするため、小規模なバッチ処理から大規模データの変換まで対応できます。処理が実行されていない時間にはコストは発生せず、運用負荷とコストの両方を抑えられます。
2. 多様なデータソースへの接続
Amazon S3をはじめ、RDS、Aurora、DynamoDB、RedshiftなどのAWSサービスや、JDBC経由の外部データベースと接続できます。Crawlerを利用すれば、データ構造を自動検出してGlue Data Catalogに登録でき、分析サービスとの連携も容易になります。複数のデータソースを横断したデータ統合に適しています。
3. 機械学習を使用した FindMatches 機能
AWS Glueには機械学習を活用した FindMatches 機能が用意されています。この機能は、表記ゆれや重複データを自動的に検出し、名寄せ処理を支援します。例えば、顧客名や住所の微妙な違いを判別し、同一データとして扱えるようにします。ルールを手動で定義しなくても高精度なデータクレンジングが可能です。
AWS Glue を使ってできること
AWS Glueは画面操作を中心に処理の流れを作成でき、データ形式の変換やリアルタイム処理にも対応しています。ここでは手作業によるデータ準備の負担を減らし、効率よくデータ活用を進める方法を紹介します。
データのリアルタイム処理が可能
Glue Streaming Jobsを利用することでリアルタイムに近いデータ処理が可能です。Kinesis Data StreamsやKafkaなどのストリーミングデータを取り込み、変換処理を行いながら即座に保存できます。
これにより、ログ分析やイベントデータ処理など、即時性が求められるユースケースに対応できます。
ノーコードでETL(抽出・変換・ロード)パイプラインを作成
AWS Glueでは、専門的なプログラミングを行わなくてもETLパイプラインを構築できます。画面操作でデータの取り込み元や変換内容、出力先を順番に設定するだけで処理の流れを組み立てられます。
これにより、データ加工の全体像を把握しながら設計できるため、ETLの仕組みを理解しやすく、学習コストを抑えてデータ処理を始められます。
複雑な形式の変換にも対応している
AWS Glueは、CSV、JSON、Parquet、ORC、Avroなど多様なデータ形式に対応しています。異なる形式間の変換やスキーマ変更もETLジョブ内で実行できます。分析用途に適した列指向フォーマットへ変換することで、AthenaやRedshiftでのクエリ性能向上にもつながります。
テーブルやセルレベルでの細かなアクセス制御
セキュリティ強化
AWS Lake Formationと連携することで、テーブルやカラム単位のアクセス制御が可能です。ユーザーやロールごとに参照可能なデータを制限でき、機密情報の漏えいを防ぎます。これにより、複数部門で同じデータを安全に共有できます。
さらに、必要な人だけが必要なデータにアクセスできる状態を維持できるため、データガバナンスを強化し、組織全体のセキュリティレベル向上につながります。
AWS Glue の料金体系
AWS Glueの料金は、処理に使ったリソース量と実行時間に応じて発生する従量課金制となっています。
例え: AWS Glue の料金は「タクシーの運賃」に似ています。
- DPU はタクシーの車種(大型か小型か)のようなもので、高性能な車を選ぶほど時間あたりの単価が上がります。
- 使用時間 に応じて料金が決まり、乗っていない時間(ジョブが動いていない時間)の基本料金はかかりません。
- Flex 実行 は「急がないので、空いている時に安く乗せてほしい」という割引プランのようなイメージです。
上記を踏まえて仕組みについて解説します。
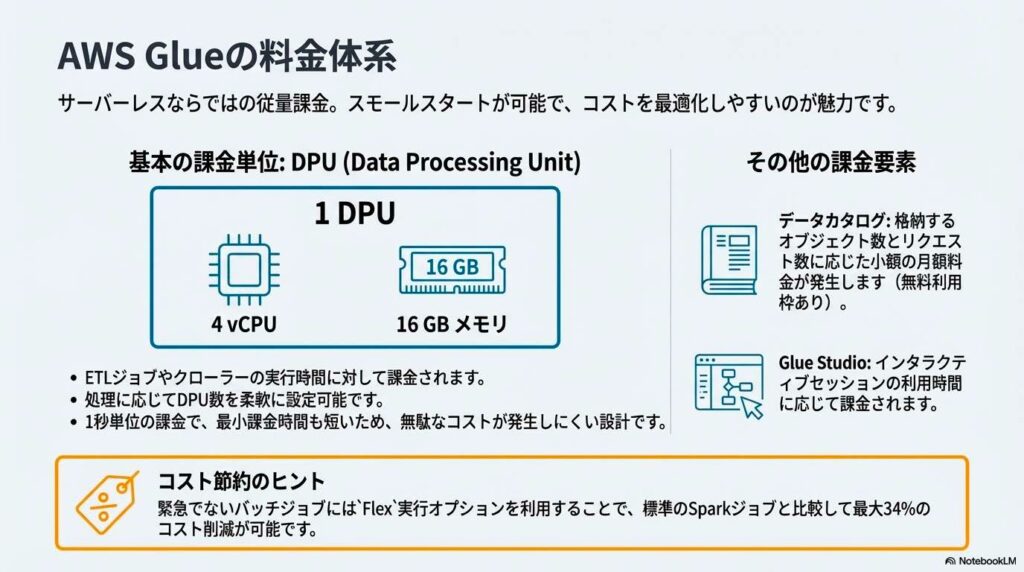
データ処理単位 (DPU) による課金
課金はDPU(Data Processing Unit)を基準に行われます。DPUはCPU、メモリ、ディスクI/Oを含む処理能力の単位で、ETLジョブやクローラーの実行時に消費されます。割り当てるDPU数が多いほど処理は高速になりますが、その分時間あたりの料金も上昇します。
処理内容に応じて適切なDPU数を選択することが、コスト最適化のポイントです。
ワークロード別の課金カテゴリ
AWS Glueでは、ETLジョブ、クローラー、開発エンドポイント、ストリーミング処理など、ワークロードごとに課金体系が分かれています。それぞれで消費されるDPUや課金単位が異なるため、用途に応じた設計が重要です。
特に、常時実行されるストリーミング処理は、バッチ処理とコスト感覚が異なります。
無料で利用できる機能
AWS Glueで用意されている無料利用枠では初期検証や学習用途で活用できます。一定時間分のETLジョブ実行やクローラー利用が対象となり、小規模なデータ処理であれば追加コストなしで試せます。本番利用前に処理内容やDPU設定を検証する手段として有効です。
例えば、S3に置いたCSVファイルをクローラーでテーブル化し、不要な列を削除して別形式で出力するETL処理や、Athenaでクエリできる状態までデータを整える一連の流れを、料金を気にせず体験できます。
AWS Glue の主要コンポーネント
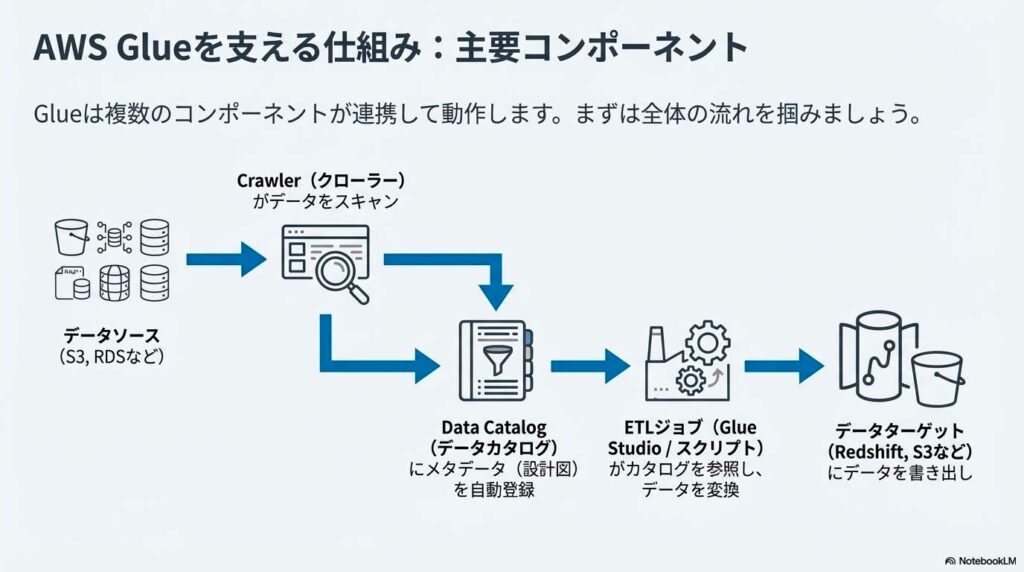
AWS Glueは、ETL処理を実現するために役割ごとに分かれた複数の機能で構成されています。データの構造を把握し、加工し、実行や管理を行うまでの工程を、それぞれ専用の機能が担います。ここでは、Glueを構成する主要コンポーネントと、その役割の違いについて解説します。
1. AWS Glue Data Catalog(データカタログ)
Glue Data Catalogは、データのメタデータを一元管理するための中核的なコンポーネントです。テーブル名、カラム構成、データ型、保存先といった情報を管理し、AthenaやRedshift、EMRなど複数の分析サービスから共通で参照されます。
これにより、分析ごとにスキーマを定義する必要がなくなり、データ管理の整合性が保たれます。Glueを使ったデータ基盤では、このカタログが全体の土台となります。
2. Crawler(クローラー)
Crawlerは、データソースを自動的にスキャンし、スキーマを検出してData Catalogに登録する機能です。Amazon S3やRDSなどを対象に実行でき、カラム構成やデータ型を自動で判別します。
定期実行を設定すれば、データ構造の変更にも追従できます。手動でテーブル定義を作成する手間を省き、データ登録作業を効率化する役割を担います。
3. ETL ジョブ(Jobs システム)
ソース、ターゲット、および変換スクリプトで構成
ETLジョブは、データの抽出・変換・ロード処理を実行する中核機能です。ソース、ターゲット、変換スクリプトで構成され、Apache Sparkを基盤として動作します。Glue Studioを使えば、スクリプトを自動生成でき、形式変換やデータ加工を視覚的に設計できます。バッチ処理だけでなく、ストリーミング処理にも対応しています。
4. トリガー
トリガーは、ETLジョブやクローラーを自動実行するための制御機能です。指定した時刻に実行するスケジュール型や、別ジョブの完了後に続けて実行する依存関係型を設定できます。これにより、複数の処理を連携させたデータパイプラインを構築できます。手作業による実行を減らし、安定した運用を実現します。
5. AWS Glue Studio
AWS Glue Studioは、ETLジョブの作成・編集・確認を一元的に行うための管理画面です。ジョブの構成や変換内容を視覚的に確認でき、処理の流れを把握しながら調整できます。
また、自動生成されたスクリプトを確認・修正することも可能なため、将来的にコードベースの運用へ移行したい場合にも対応できます。
AWS Glue の利用方法
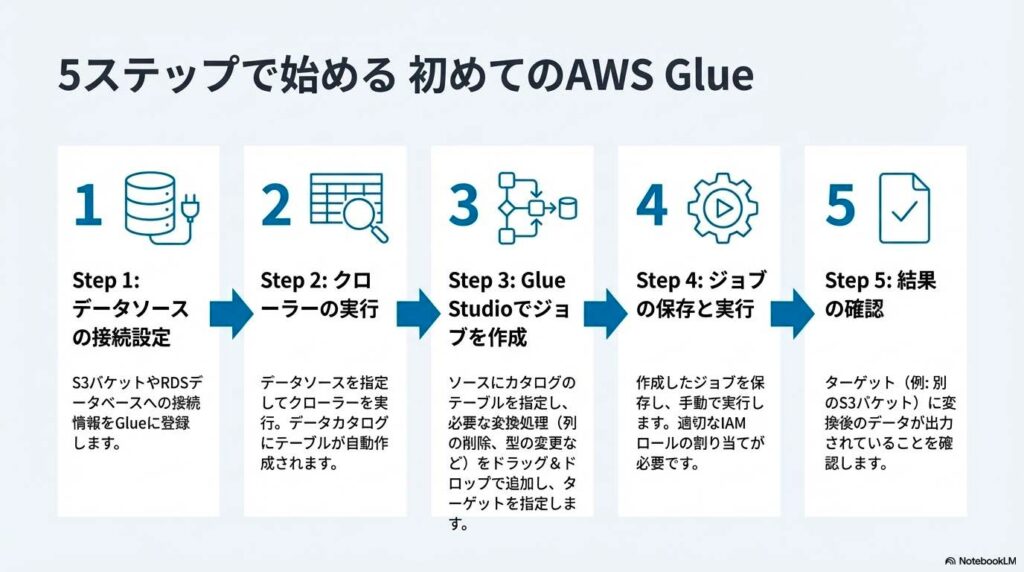
AWS Glueを使ってデータを登録し、加工し、分析サービスで活用するまでの基本的な手順を初心者向けに解説します。この手順を行うことで初心者でも簡単にGlueを始めることができます。
ステップ1:事前準備 (IAM)
最初に、GlueがAWSリソースへアクセスするためのIAMロールを用意します。このロールには、S3への読み書き権限やGlueジョブの実行権限を付与します。多くの場合、AWSが用意しているAWSGlueServiceRoleを利用すれば、基本的な設定は十分です。
IAM設定が不十分だと、クローラーやETLジョブが途中で失敗する原因になります。そのため、最初に権限を正しく設定しておくことが、安定した運用につながります。
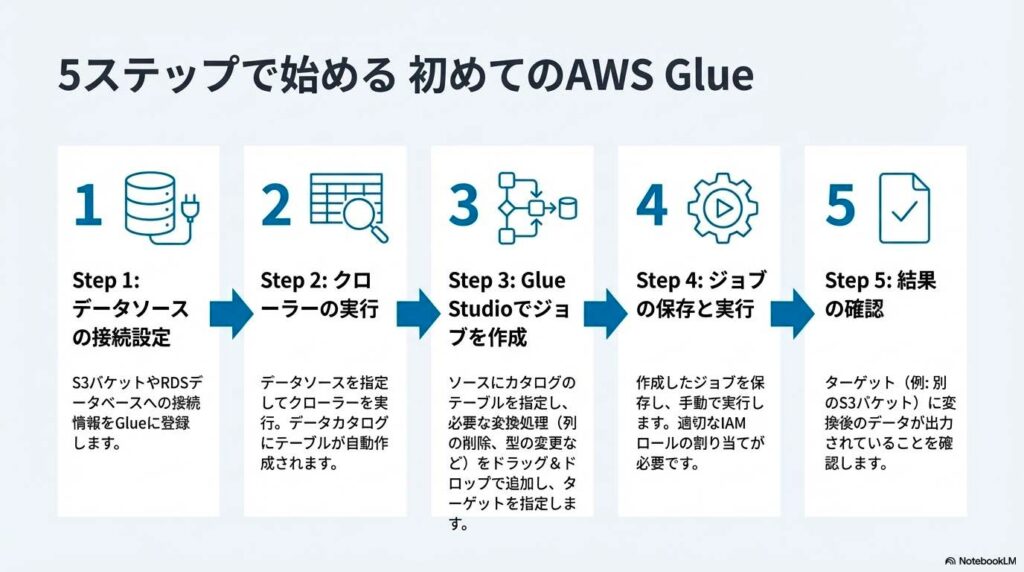
ステップ2:クローラーでデータ登録
AWSマネジメントコンソールでGlueを開き、「クローラーの作成」を選択します。データの保存先としてS3バケットやデータベースを指定し、IAMロールを設定するだけで準備は完了です。クローラーを実行すると、データ形式やカラム構成、データ型が自動的に解析され、Glue Data Catalogにテーブルが作成されます。
この工程により、S3上のファイルをそのまま扱うのではなく、データベースのテーブルとして参照できるようになります。AthenaやETLジョブから利用するための土台となる重要な作業です。
ステップ3:ETLジョブの作成
データがカタログに登録されたら、ETLジョブを作成します。AWS Glueの管理画面から「ETL jobs」を開き、「Visual ETL」を選択します。画面上でデータソースと出力先を指定し、変換処理を追加していくだけでETLジョブを作成できます。コードを書く必要はなく、設定内容に応じてスクリプトが自動生成されます。
ここでは、不要な列の削除、データ形式の変換、値の加工などを定義します。この処理によって、分析や可視化に適したデータ構造を作成できます。
ステップ4:ジョブの実行とスケジューリング
作成したETLジョブは、Glueのジョブ一覧画面から手動で実行できるだけでなくトリガーを使った自動実行が可能です。スケジュールを設定すれば、毎日や毎時間など定期的にデータ処理を行えます。
また、別のジョブやクローラーの完了後に実行する設定もできます。これにより、データ更新作業を自動化でき、運用時の手作業を減らせます。
ステップ5:分析ツールにデータを送信
ETL処理が完了したデータは、Amazon AthenaやAmazon Redshiftなどの分析サービスから利用します。Glue Data Catalogに登録されたテーブルを参照することで、SQLによる検索や集計が可能になります。
Glueでデータを整え、Athenaで分析するという役割分担により、効率的で拡張性の高いデータ分析基盤を構築できます。
まとめ
AWS Glueは、データを抽出・変換・ロードするETL処理をサーバーレスで実行できる強力なサービスです。Glueでデータを整え、Athenaで分析することで、効率的なデータ活用基盤を構築できます。料金はDPUと実行時間に基づく従量課金のため、無駄なコストが発生しにくい点も魅力です。
ノーコード開発や自動スキーマ管理など、初心者でも扱いやすい機能が揃っているため、AWSでのデータ分析を始める第一歩としてぜひ使ってみてください。

