
クラウド上でアプリケーションを構築する際、データベースの選定はパフォーマンスや可用性、運用コストに大きな影響を与えます。
AWSが提供する Amazon Aurora(アマゾン・オーロラ) は、高性能・高可用性を実現したフルマネージド型のリレーショナルデータベースです。
本記事では、「そもそもAuroraとは何か?」という基礎的な内容から、Auroraの特徴や構成要素、料金体系、実際のデプロイ手順、基本的な操作方法までを順を追って解説します。
Aurora とは?
Amazon Aurora(アマゾン・オーロラ)は、AWSが提供するフルマネージド型のリレーショナルデータベースサービスです。MySQLおよびPostgreSQLと互換性を持ちながら、クラウド環境に最適化された独自のアーキテクチャを採用しており、高性能と高可用性を両立しています。
従来のオンプレミス型データベースでは、サーバー管理やバックアップ、障害対応といった運用作業に多くの工数が必要でした。Auroraではこれらの運用をAWS側が担うため、利用者はデータベース管理に煩わされることなく、アプリケーション開発に集中できます。
また、自動スケーリングや高い耐障害性を備えており、アクセス量が変動しやすいクラウド特有のワークロードにも柔軟に対応できます。スタートアップから大規模システムまで、幅広い用途で利用されている点も特徴です。
そもそもデータベースとは?
データベースとは、アプリケーションで利用するデータを効率的かつ安全に保存・管理するための仕組みです。ユーザー情報や商品データ、取引履歴など、システムの中核となる情報はデータベースに格納されます。
リレーショナルデータベース(RDB)は、表形式でデータを管理し、SQLと呼ばれる専用言語を使って検索や更新を行います。データの整合性を保ちやすく、業務システムやWebサービスで長年利用されてきました。
一方で、高い可用性や性能を維持するためには、冗長構成やバックアップ設計など専門的な知識が求められる点が課題とされてきました。
RDSとは?
RDSファミリーの中に Aurora が含まれることを説明
Amazon RDS(Relational Database Service)は、AWSが提供するリレーショナルデータベースのマネージドサービスです。
MySQL、PostgreSQL、MariaDB、Oracle、SQL Serverなど複数のデータベースエンジンを簡単に利用でき、バックアップやパッチ適用、障害対応といった運用作業をAWSが自動化します。
Amazon Auroraは、このRDSファミリーの一つとして提供されており、従来のRDSエンジンと比べて、よりクラウドネイティブな設計が施されています。
RDSの使いやすさを維持しながら、より高い性能と可用性を実現している点がAuroraの大きな特徴です。用途や規模に応じてデータベースを選択できる点も、RDSファミリー全体のメリットです。
Auroraの特徴
Amazon Auroraは、クラウド環境に最適化された設計により、高性能・高可用性・高い拡張性を兼ね備えたリレーショナルデータベースです。ここでは、代表的な特徴を紹介します。
高性能(最大5倍のスループット)
MySQL互換エンジンでは最大5倍、PostgreSQL互換エンジンでも最大3倍程度のスループットを実現するとされています。これは、データベースエンジンとストレージ層を分離し、ログ構造ストレージを採用することで、ディスクI/Oを効率化しているためです。
従来のデータベースでは書き込み処理が性能のボトルネックになりがちでしたが、この設計により、読み書きの多いワークロードでも安定したパフォーマンスを発揮します。
高可用性と耐障害性
3つのAZに自動複製,フェイルオーバー数十秒
1つのリージョン内で3つのアベイラビリティゾーン(AZ)にまたがってデータが自動的に複製され、合計6つのストレージコピーが保持されます。一部のAZやストレージに障害が発生しても、サービスを継続できる高い耐障害性を備えています。
万が一、Writerインスタンスに障害が発生した場合でも、数十秒程度で自動フェイルオーバーが行われ、Readerインスタンスが昇格します。これにより、ダウンタイムを最小限に抑えた運用が可能です。
スケーラビリティ
ストレージ容量が自動的に拡張される仕組みを持っており、事前に容量を見積もる必要がありません。データ量の増加に応じて、最大128TBまで自動的にスケールするため、長期運用でも安心して利用できます。
また、Readerインスタンスを追加することで読み取り性能を水平スケールでき、アクセス数の増減が大きいシステムにも柔軟に対応できます。
自動バックアップ・スナップショット
データの変更内容は継続的にAmazon S3へバックアップされ、自動バックアップが標準で有効化されています。指定した保持期間内であれば、任意の時点に復元できるポイントインタイムリカバリも利用可能です。
さらに、手動でスナップショットを取得することもでき、バックアップ運用を強く意識せずに高い安全性を確保できます。
Auroraの構成要素
Amazon Auroraは、従来のデータベースとは異なる独自の構成を採用することで、高い性能と可用性を実現しています。Auroraを理解するうえでは、「クラスター」「インスタンス」「エンジンとクラス」という3つの構成要素を押さえておくことが重要です。ここでは、それぞれの役割や関係性について、順を追ってわかりやすく解説します。
Aurora クラスター
クラスターは、データベース全体を管理する論理的な単位です。アプリケーションは、クラスターに割り当てられたエンドポイントを通じて接続します。
実際のデータは、クラスターに紐づく分散ストレージに保存され、3つのアベイラビリティゾーン(AZ)へ自動的に複製されます。この仕組みにより、インスタンスに障害が発生した場合でもデータが失われにくい構造になっています。インスタンスの追加や削除を行ってもデータが保持され続ける点も大きな特徴です。
Aurora インスタンス(Writer / Reader)
クラスターの中には、1つ以上のAuroraインスタンスが存在します。Writerインスタンスはデータの書き込みを担当し、クラスター内に必ず1つだけ配置されます。
一方、Readerインスタンスは読み取り専用で、複数追加することが可能です。Readerを増やすことで読み取り性能を向上させ、負荷分散を行えます。
Writerに障害が発生した場合でも、Readerの一つが自動的に昇格するため、高い可用性が保たれます。
エンジンとクラス
利用するデータベースエンジンとして、MySQL互換エンジンまたはPostgreSQL互換エンジンを選択できます。既存のアプリケーションやSQL資産を活かしやすく、移行のハードルが低い点が特徴です。
また、インスタンスクラスはCPUやメモリ性能を表しており、ワークロードに応じたサイズを選択します。
適切なエンジンとクラスを選ぶことで、安定したパフォーマンスと効率的な運用が可能になります。
Auroraの料金体系
Provisioned と Serverless があることに触れて、それぞれの料金体系を大まかに解説してほしいです。詳しく解説する必要はないです。
「詳細はカリキュレーターを確認してください。」という文章を入れてください。
Amazon Auroraの料金は、「Provisioned」と「Serverless」の2つの利用形態によって構成されています。
Provisionedは、あらかじめインスタンスサイズを指定して利用する方式です。インスタンスの稼働時間に応じた料金に加え、使用したストレージ容量やI/Oに対して課金されます。一定の負荷が継続する業務システムや、安定した性能が求められる環境に向いています。
一方、Aurora Serverlessは、アクセス量に応じてデータベースのキャパシティが自動的に調整され、実際に使用した分だけ課金される仕組みです。負荷の変動が大きいシステムや、初期コストを抑えたいケースに適しています。
具体的な料金は、利用するリージョンや構成によって異なります。詳細はAWSの料金カリキュレーターを確認してください。
Auroraのデプロイ方法
ここではAWSマネジメントコンソールの画面操作を前提に、Aurora Serverless(Serverless v2)をデプロイするまでの流れを初心者向けに解説します。 まずはVPCなどのネットワーク環境を整え、その後にAuroraクラスターを作成することで、セキュリティと可用性を確保した構成を構築します。
STEP 1:VPC を作成する
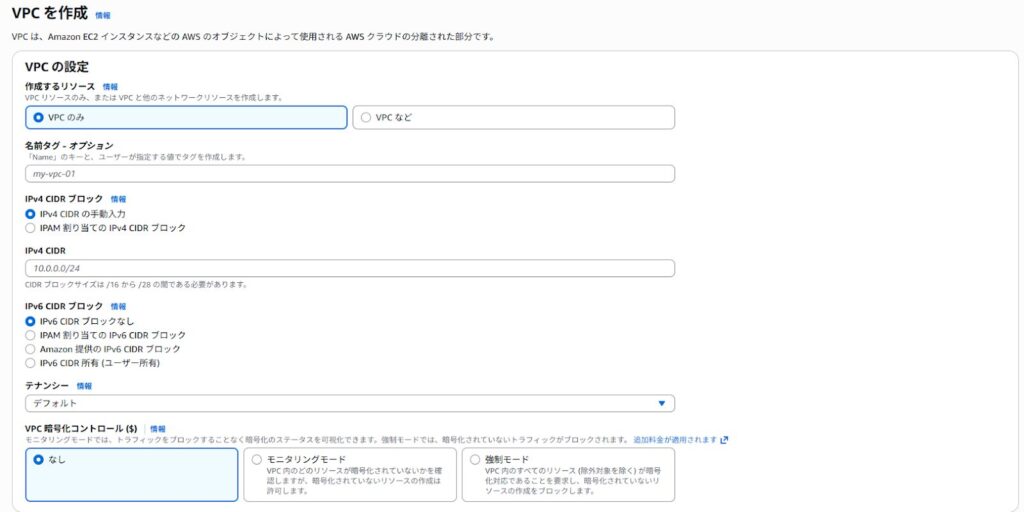
AWSマネジメントコンソールで「VPC」と検索し、VPCダッシュボードを開きます。「VPCを作成」ボタンをクリックし、【作成するリソース】で「VPCのみ」を選択し、VPC名、IPv4 CIDR(例:10.0.0.0/16)を入力します。その他の項目はデフォルトのままで問題ありません。
もし「VPCなど」を選択した場合はサブネット(パブリック/プライベート)、ルートテーブル、インターネットゲートウェイ、NATゲートウェイ(※要選択)すべてが一緒に作成されますので、STEP2~5は飛ばしてください。
STEP 2:プライベートサブネットを作成する
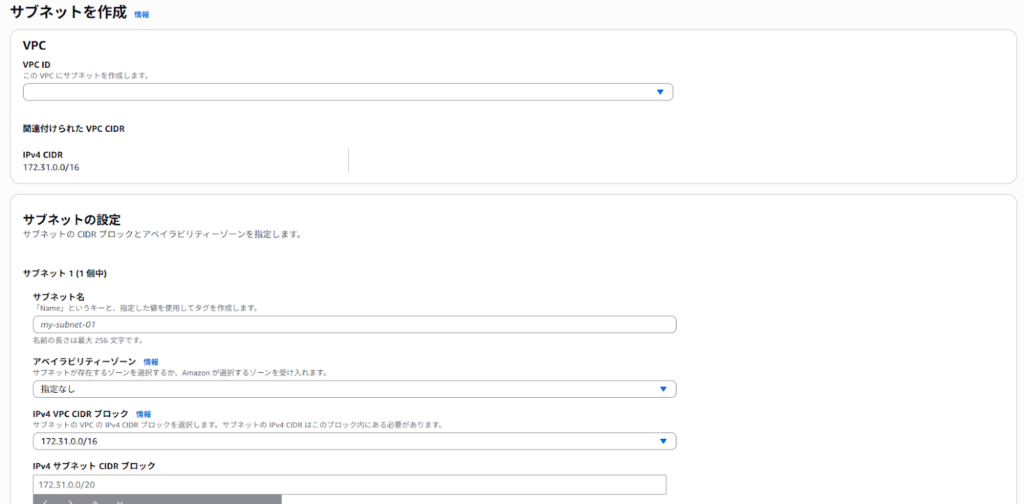
左メニューの「サブネット」から「サブネットを作成」を選択します。先ほど作成したVPCを指定し、異なるアベイラビリティゾーン(AZ)に複数のパブリックサブネットとプライベートサブネットを作成します。
STEP 3:ルートテーブルを作成し、サブネットに関連付ける
左メニューの「「ルートテーブル」から「ルートテーブルを作成」をクリックします。
作成後、「サブネットの関連付け」タブから、先ほど作成したプライベートサブネットを関連付けます。
この時点ではインターネットへのルートは設定しません。
STEP 4:インターネットGWを作成し、VPC にアタッチする
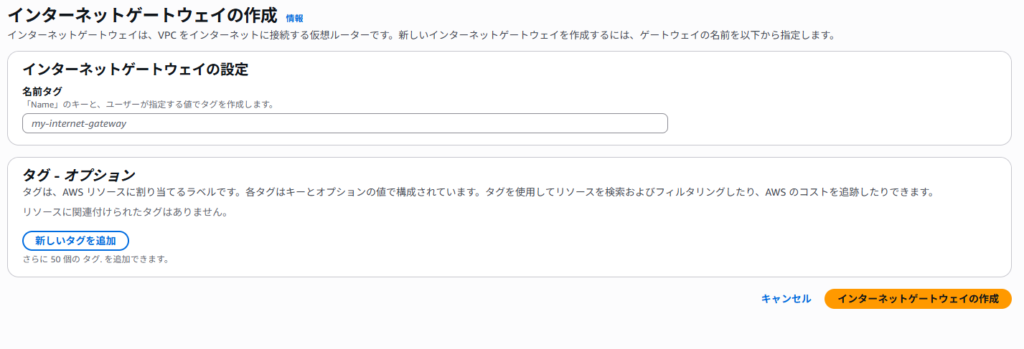
「インターネットゲートウェイ」から「インターネットゲートウェイを作成」をクリックします。
作成後、「アクション」→「VPCにアタッチ」を選択し、対象のVPCを指定します。これは後続のNAT Gatewayで利用します。
STEP 5:NAT Gateway を作成する

プライベートサブネット内のリソースがインターネット経由でAWSサービスにアクセスできるようにするため、NAT Gatewayを作成します。
「NATゲートウェイを作成」をクリックし、配置するサブネットにはパブリックサブネットを選択します。
Elastic IPを割り当てたら作成し、プライベートサブネット用のルートテーブルに「0.0.0.0/0 → NAT Gateway」のルートを追加します。
STEP 6:必要な VPC Endpointを作成する(任意)
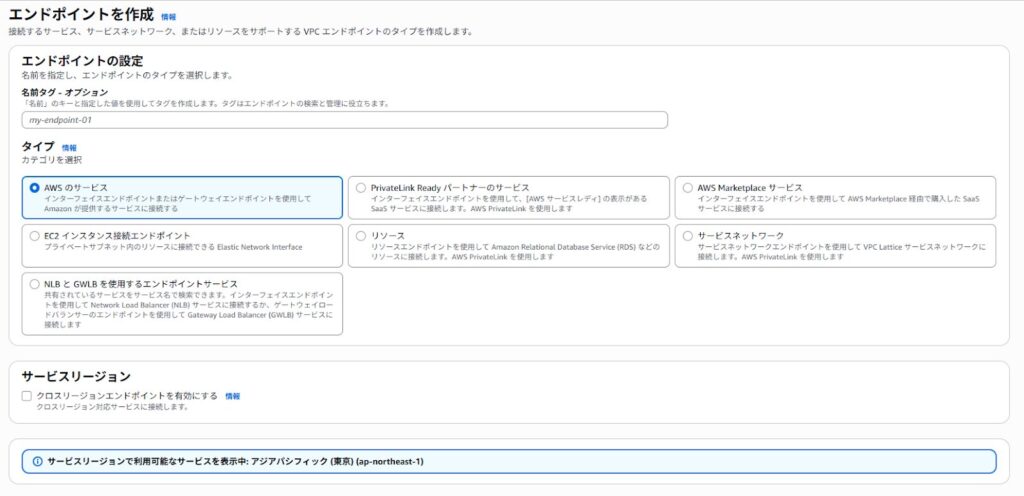
Secrets Manager や CloudWatch Logs をインターネットを経由せずに利用したい場合は、VPC Endpointを作成します。
学習用途や検証環境であれば、この手順は省略しても問題ありません。
「VPCエンドポイント」から「エンドポイントを作成」を選択します。
Secrets Manager、SSM、CloudWatch Logs などを選び、VPCとプライベートサブネットを指定します。これにより、インターネットを経由せずにAWSサービスへアクセスできます。
STEP 7:Aurora 用のセキュリティグループを作成する
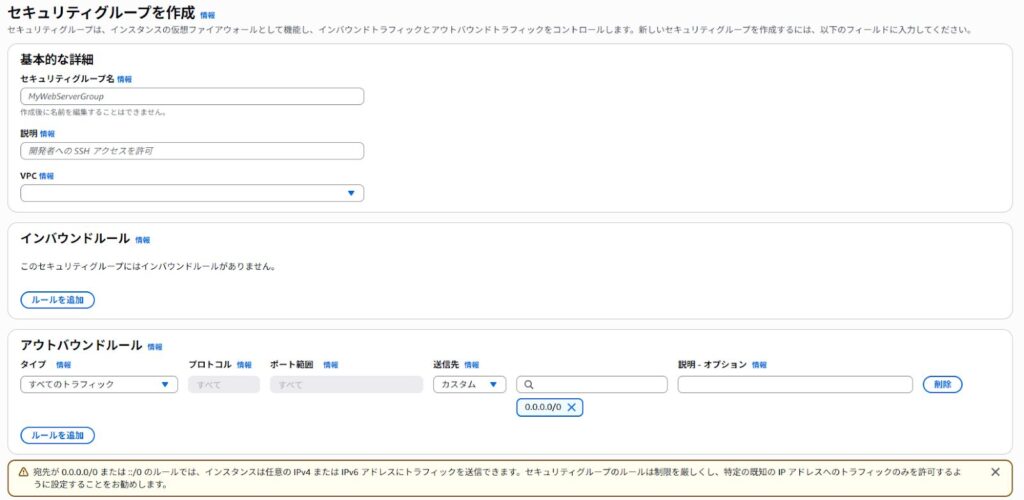
EC2の「セキュリティグループ」画面で「セキュリティグループを作成」をクリックします。VPCを指定し、インバウンドルールにデータベースのポート(MySQLなら3306、PostgreSQLなら5432)を設定します。
STEP 8:DB Subnet Group を作成する
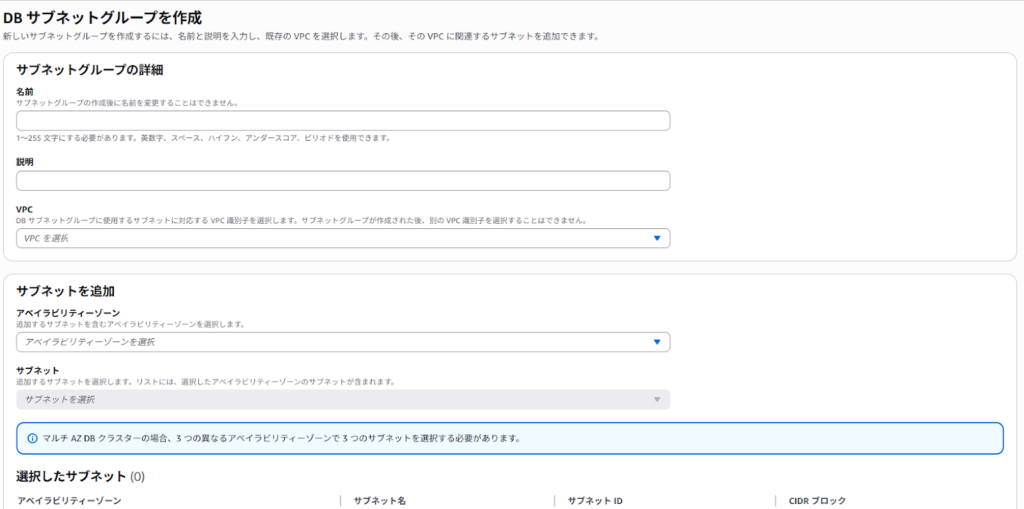
RDSコンソールに移動し、「サブネットグループ」→「DBサブネットグループを作成」を選択します。VPCを指定し、複数AZにまたがるプライベートサブネットを追加します。これによりAuroraの高可用性が確保されます。
STEP 9:Aurora Serverless クラスターを作成する
RDSの「データベースを作成」ボタンをクリックし、【データベース作成方法を選択】を「フル設定」にします。【エンジンのタイプ】で「Amazon (Aurora Compatible)」を選択します。
【接続】で作成したVPC、セキュリティグループ、DBサブネットグループを指定します。設定内容を確認し、問題なければ作成を実行します。
STEP 10:Aurora クラスター内に DB インスタンスを作成する
Aurora Serverless v2 では、クラスター作成時に必要なDBインスタンスもあわせて作成されます。
作成完了後は、クラスター詳細画面でエンドポイントを確認し、アプリケーションから接続できる状態になっているかを確認します。これでAurora環境のデプロイは完了です。
Auroraの基本操作
Auroraを実際に利用するためには、データベースへ安全に接続し、基本的なSQL操作を行えるようになることが重要です。
ここでは、踏み台サーバーを使用せずに接続できる「SSM Session Manager Port Forwarding」を使った接続方法を中心に、接続情報の確認と簡単なテーブル作成までの流れを初心者向けに解説します。
SSM Session Manager Port Forwardingを使ってAuroraに接続しよう
SSM Session Managerを利用すると、SSHやRDPのポートを開放することなく、EC2インスタンスを経由して安全にデータベースへ接続できます。この方法では、EC2を踏み台として使用し、ローカルPCのポートをAuroraのエンドポイントへ転送します。
事前に、対象のEC2インスタンスにSSM Agentがインストールされており、IAMロールに「AmazonSSMManagedInstanceCore」が付与されていることを確認してください。
また、EC2がAuroraと同じVPC内にあり、セキュリティグループでデータベースポートへの通信が許可されている必要があります。
準備が整ったら、AWS Systems Managerの「セッションマネージャー」画面から「セッションを開始」をクリックし、対象のEC2を選択します。
Port Forwarding を設定すると、ローカルPCのポート(例:3306)をAuroraのエンドポイントに転送でき、MySQLクライアントなどから接続できるようになります。
接続情報(ホスト名・ポート・ユーザー)を確認しよう
データベースへ接続する前に、必要な接続情報を確認しておきます。RDSコンソールで対象のAuroraクラスターを選択し、「接続とセキュリティ」タブを開くと、WriterエンドポイントとReaderエンドポイントが表示されます。
ホスト名には、書き込みを行う場合はWriterエンドポイントを使用します。
ポート番号は、MySQL互換エンジンの場合は3306、
PostgreSQL互換エンジンの場合は5432が一般的です。
ユーザー名とパスワードは、クラスター作成時に設定したものを使用します。これらの情報を事前に整理しておくことで、接続時のトラブルを防げます。
テーブル作成(CREATE TABLE)をしよう
接続が完了したら、実際にSQLを実行してみましょう。まず「USE データベース名;」を実行し、操作対象のデータベースを指定します。
次に、以下のようなSQLを実行します。
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100)
);エラーなく実行できれば、テーブルの作成は完了です。このように簡単な操作を試してみることで、Auroraへの接続や基本的な動作を確認できます。
まとめ
Amazon Auroraは、高性能・高可用性を備えたAWSのフルマネージドRDBです。rovisioned と Serverless の2つの利用形態を使い分けることで、さまざまなシステム要件に対応できます。
本記事を通じて、Auroraの仕組みや基本操作を理解し、運用負荷を抑えながら安定したデータベースを構築するための参考にしてください。

