SageMakerを使って機械学習モデルを構築する際、多くの人がモデル学習やアルゴリズムに注目しがちですが、実務で成果を左右するのは「データ処理」です。
Notebookで前処理を行うことはできますが、データ更新や再学習を繰り返す運用では限界が見えてきます。こうした課題を解決するのが SageMaker Processing です。
本記事では、SageMakerにおけるデータ処理の役割を整理しながら、Processingの仕組みや活用シーンをわかりやすく解説します。
なぜ機械学習には「データ処理」が必要なのか

機械学習モデルは、入力されるデータの品質によって性能が大きく左右されます。
どれだけ高度なアルゴリズムを使っても、前処理が不十分であれば期待する精度は出ません。
ここでは、データ処理がなぜAI開発に欠かせないのか、その理由を整理します。
AIの精度の8割はデータ処理で決まる
機械学習の精度は、モデル構造やアルゴリズムだけで決まるものではありません。
実際には、入力されるデータの質が結果を大きく左右します。
欠損値や外れ値、ラベルの揺れが残った状態で学習を行うと、モデルは本来捉えるべき特徴とは異なるパターンを学習してしまいます。
その結果、精度が伸び悩んだり、推論が不安定になることもあります。
このため実務の現場では「精度の8割はデータ処理で決まる」と言われています。
Notebookだけの前処理が運用で破綻する理由
Notebookで前処理を行うこと自体は手軽で、検証フェーズでは有効な手段です。
しかし、データ更新や再学習を前提とした運用に入ると、次第に課題が表面化します。
データの更新ごとにNotebookを開いて手動で実行する必要があり、作業が特定の担当者に依存しやすくなります。
また、実行順序の違いやライブラリのバージョン差分によって、同じコードでも結果が変わることがあります。
こうした状態が続くと処理の再現性が失われ、安定した運用が難しくなっていきます。
結果として、前処理そのものがボトルネックとなり、モデル改善に集中できなくなるケースも少なくありません。
SageMakerのデータ処理に求められる要件
SageMakerでデータ処理を行う以上、前処理には一定の要件が求められます。
まず重要なのが再現性です。
同じデータと同じコードを使えば、実行するたびに同じ結果が得られなければなりません。
次に、自動化できることも欠かせません。
データ更新のたびに人が介在する仕組みでは、運用はすぐに行き詰まります。
さらに、扱うデータ量が増えたときに処理性能を柔軟に拡張できるかどうかも重要なポイントです。
SageMaker Processingは、こうした実務上の要件を前提として設計されています。
SageMaker Processingとは?基本の仕組みを理解する

SageMaker Processingは、機械学習におけるデータ前処理を「ジョブ」として切り出し、安定して実行するための仕組みです。
Notebookでの試行錯誤とは役割が異なり、再現性と運用性を重視したデータ処理を担います。
ここでは、その基本的な考え方と動作の全体像を整理します。
Processingが担うデータ前処理の範囲
SageMaker Processingが担うのは、モデル学習に入る前段階のデータ処理です。
欠損値の補完や外れ値の除去といったクリーニング処理に加え、特徴量の生成や不要な列の削除、さらには学習用・検証用データへの分割なども対象になります。
一方で、モデルの学習や推論そのものはProcessingの役割ではありません。
あくまで「学習に適したデータを、安定して作り出すこと」に専念する位置づけです。
前処理をこの工程として明確に分離することで、学習処理との責務が整理され、
全体のワークフローを見通しやすくなります。
ジョブとして実行されるProcessingの動作フローを理解する
Processingは、Processing Jobとして実行されます。
ジョブが起動すると、指定したインスタンスタイプとコンテナ環境が用意され、
その中でユーザーが定義した前処理スクリプトが実行されます。
入力データはS3からコンテナ内に読み込まれ、処理結果は再びS3へ出力される仕組みです。
この一連の流れはジョブ単位で管理されるため、
「いつ、どのコードで、どのデータを処理したのか」を後から追跡できます。
Notebookのように状態が残らない点も、運用上の大きな特徴です。
Notebookとの違いは「スケールと再現性」にある
Notebookは、前処理ロジックを検証したり試行錯誤したりする用途に適しています。
その一方で、実行環境やセルの実行順序に依存しやすく、同じ結果を安定して再現することは得意ではありません。
Processingでは、実行環境がコンテナとして固定され、毎回同じ条件でジョブが実行されます。
また、データ量に応じてインスタンスサイズを変更できるため、処理規模が拡大しても対応しやすくなります。
このスケールと再現性の違いが、NotebookとProcessingを使い分ける際の大きな判断軸になります。
Processingで実現できるデータ処理の種類

SageMaker Processingは、単なる前処理の実行環境ではありません。
機械学習の品質と運用性を支えるために、さまざまなデータ処理を安定して実行できます。
ここでは、実務でよく利用される代表的な処理内容を整理します。
欠損値補完や型変換など、基礎的なクリーニング処理を自動化する
Processingは、欠損値補完や外れ値の除去、データ型の変換といった基本的なクリーニング処理に適しています。
これらの処理は一見単純ですが、手作業やNotebookで行っていると、処理漏れや条件の違いが発生しやすくなります。
Processingでスクリプトとして定義しておけば、毎回同じルールで前処理を実行できます。
データ更新が頻繁に発生する場合でも、処理内容を意識する必要はありません。
前処理を安定させることで、後続の学習や評価に集中できる環境が整います。
特徴量エンジニアリングを安定して実行するための土台として使う
モデルの精度を左右する特徴量エンジニアリングは、単なる計算以上に複雑なロジックを伴うことが多く、計算負荷も高くなりがちです。
SageMaker Processingを使えば、正規化、標準化、ワンホットエンコーディングといった重い処理を、学習環境から切り離して独立したジョブとして実行できます。
これにより、学習コード(Train)と前処理コード(Preprocessing)の依存関係が整理され、特徴量の生成ロジックのみを柔軟にアップデートしたり、異なるモデル間で前処理済みデータを再利用するなどが可能になります。
実務における開発サイクルを加速させる強力な土台となるでしょう。
学習用データの分割や形式変換を一括で行う
生データを「学習用・検証用・テスト用」に分割する際、ランダムシードの固定や分割比率の管理をNotebook上で行うと、再現性の欠如に繋がります。
Processingを活用することで、これらの分割作業をスクリプトとして厳密に管理し、毎回同じルールでデータセットを作成できます。
また、CSVからRecordIOやParquetといった、SageMakerの学習アルゴリズムが高速に読み込めるバイナリ形式への変換も同時に行うことが可能です。
これにより、後続の学習パイプライン全体の実行スピードを最適化し、ストレージ効率と計算効率の両方を最大化できるメリットがあります。
大量データでも安定して処理できる「スケールアウト」の強み
扱うデータ量が数GB、数TBと増えていくと、ローカル環境やNotebookのメモリ不足が大きな壁となります。
Processingの最大の強みは、インフラの制約を意識せずに済むスケーラビリティにあります。
ジョブ実行時に必要なスペックのインスタンスを自由に指定できるだけでなく、複数のインスタンスを立ち上げてデータをシャッディング(分散)して処理させることも可能です。
データの肥大化に合わせて、コードを書き換えることなくインフラ側を柔軟に拡張できるため、将来的なデータ増加を見越した設計が容易になります。
利用できるProcessorの種類と使い分け

SageMaker Processingでは、実行したい処理の内容やデータ規模に応じて、最適な「Processor」を選択できます。
これらはあらかじめ環境が整ったマネージドなクラスとして提供されており、用途に合わせて使い分けることで開発効率が大幅に向上します。
柔軟なPythonスクリプトで処理できるScriptProcessor
ScriptProcessorは、特定のフレームワークに依存せず、独自のPythonスクリプトやシェルスクリプトを自由な環境で実行したい場合に最適です。
ベースとなるDockerイメージを指定できるため、標準的なライブラリだけで構成される軽量な処理から、OSレベルの設定が必要な処理まで幅広く対応可能です。
汎用性が極めて高く、既存の資産を最小限の修正でジョブ化したいシーンで最も重宝されるProcessorです。
機械学習前処理に強いSKLearnProcessorの適用シーン
scikit-learnを用いたデータ加工に特化しているのがSKLearnProcessorです。
AWSが最適化したマネージドな環境が提供されているため、自分でDockerイメージを管理する必要がありません。
欠損値補完やスケーリング、エンコーディングといった一般的な機械学習の前処理であれば、これを選択するのが最短ルートです。
使い慣れたscikit-learnのロジックを、そのままスケーラブルな環境で実行できる点が魅力です。
大規模データ向けのPySparkProcessorを選ぶべきケース
テラバイト級の大規模データを並列分散処理する必要がある場合は、PySparkProcessorを選択します。
通常、Spark環境の構築やクラスター管理には多大な工数がかかりますが、これを利用すればマネージドな環境で即座に分散処理を開始できます。
複雑なETL処理や、単一インスタンスのメモリには収まりきらない巨大なデータセットを扱うプロジェクトにおいて、インフラの複雑さを隠蔽しつつ高いパフォーマンスを発揮します。
特殊な処理や依存ライブラリが多い場合はカスタムコンテナで対応
標準のProcessorでは対応できない特殊なバイナリや、社内独自のプライベートライブラリを組み込みたい場合は、カスタムコンテナを使用します。
自身で作成したDockerイメージをAmazon ECRにプッシュし、それをProcessingから呼び出すことで、完全にコントロールされた実行環境を構築できます。
再現性を極限まで高めたい場合や、複雑な依存関係を持つプロジェクトにおいて、究極の柔軟性を提供する選択肢となります。
Processingの入力・出力の仕組み
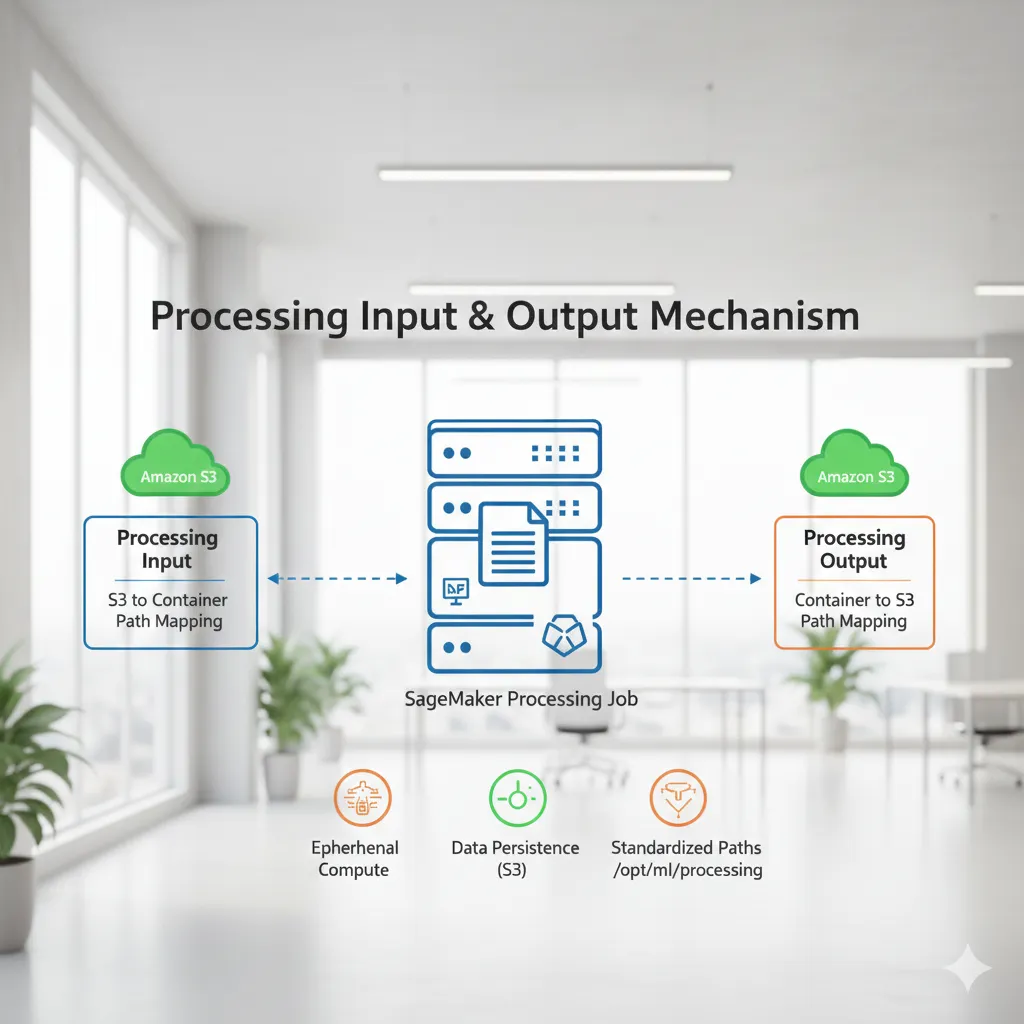
Processing Jobの核心は、データの永続化を担うS3と、一時的な計算リソースであるコンテナ間のシームレスな連携にあります。
このデータの流れを正しく理解することが、安定したパイプライン構築の第一歩となります。
S3を介したデータ受け渡しがどのように設計されているか
Processing Jobは、実行のたびに使い捨ての計算環境が起動する仕組みです。
そのため、ジョブ開始時にS3から必要なデータをコンテナへコピーし、処理が終わると成果物をS3に書き戻した上でインスタンスを破棄します。
この「疎結合」な設計により、ストレージコストを最小限に抑えつつ、計算リソースを必要な時だけ確保できます。
データと計算が分離されているため、大規模な処理でも安全かつ効率的に管理できるのが特徴です。
ProcessingInput と ProcessingOutput の役割と設定方法
SageMaker SDKでは、「ProcessingInput」と「ProcessingOutput」を使用してデータ経路を定義します。
Inputでは「S3のどのパスを、コンテナ内のどのパスに同期するか」を指定し、Outputでは「コンテナ内のどのパスの結果を、S3のどの場所へ戻すか」を設定します。
このマッピングをSDK側で明示的に定義しておくことで、スクリプト内からは外部接続を意識せず、単なるローカルファイル操作としてコードを書くことが可能になります。
実務でよく使われる入出力ディレクトリ構造を押さえる
実務では、コンテナ内の「/opt/ml/processing/」配下を標準的な作業領域として利用します。
具体的には、入力データは「/opt/ml/processing/input」、出力データは「/opt/ml/processing/output」といったディレクトリ構造にするのが一般的です。
このパスをチーム内で統一しておくことで、複数の開発者が関わるプロジェクトでも「どこにデータがあり、どこに書き出すべきか」が明確になり、スクリプトの再利用性や保守性が飛躍的に向上します。
Processingを導入すると何が改善されるのか

SageMaker Processingを導入することで、データ処理は「個人の作業」から「システム化されたプロセス」へと進化します。
自動化、再現性、スケーラビリティの確保により、機械学習プロジェクト全体の信頼性が向上します。
前処理を自動化し、人手作業から解放されるワークフローに変わる
一度Processing Jobとして定義すれば、SDKやAPIを通じて1コマンドで実行可能になります。
SageMaker Pipelinesなどのオーケストレーションツールと組み合わせれば、新しいデータが届いたことを検知して前処理から学習までを完全に自動化することも容易です。
データサイエンティストが毎回手動でNotebookを立ち上げ、セルを順番に実行するといった非効率な作業から解放され、より本質的なモデル改善に集中できるようになります。
どの環境でも同じ結果を得られる「再現性」が確保される
コンテナ技術を利用して実行環境を固定するため、「開発者の環境では動いたが、本番環境ではエラーになる」といった問題が根絶されます。
使用するライブラリのバージョンや実行順序がジョブ単位でカプセル化されるため、数ヶ月後に同じジョブを再実行しても、全く同じ結果を確実に得ることができます。
この高い再現性は、厳密な管理が求められる商用環境や、チームでの共同開発において、プロジェクトの信頼性を担保する重要な鍵となります。
必要な処理量に応じてリソースを柔軟に拡張できる
データの規模に合わせて、計算リソース(CPU、メモリ、インスタンス数)を自由に変更できるのが大きなメリットです。
検証用の小さなデータであれば安価なインスタンスを使用し、本番用の膨大なデータにはハイスペックなリソースを割り当てるといった柔軟な運用が可能です。
Notebook環境のように固定されたリソースに縛られることがないため、処理待ち時間の短縮とコストの最適化を、高い次元で両立させることができます。
MLOpsの基盤として前処理をジョブ化できる意義
前処理をジョブ化することは、単なる効率化を超え、MLOps(機械学習オペレーション)を構築する上での一歩目となります。
各ジョブの実行履歴がログとして残るため、いつ、どのコードで、どのデータを処理したかの追跡が可能になります。
これにより、モデルの品質低下時の原因究明が迅速化されるとともに、CI/CDパイプラインへの組み込みも容易になり、持続可能な機械学習システムの運用を実現する強固な基盤が整います。
まとめ
本記事では、SageMaker Processingの役割とその重要性について解説しました。
機械学習において、データ処理は精度の8割を決めると言われるほど重要な工程です。
Notebookでの試行錯誤から一歩進み、Processingによる「ジョブ」としてのデータ処理を導入することで、再現性、自動化、スケーラビリティといった実務に不可欠な要素を手に入れることができます。
最初はコンテナやS3との連携に戸惑うかもしれませんが、一度仕組みを構築すれば、その後の運用負荷は劇的に軽減されます。