前回はSageMaker Processingを使って、データの「前処理」という機械学習の土台作りを解説しました。
今回は、いよいよ本番となる「モデル学習(Training)」に挑戦します。
機械学習のメインと言えるフェーズですが、データの置き場所や権限設定、さらにはアルゴリズム特有のお作法などでつまずく方も少なくありません。
本記事では、バケット作成やデータ転送をコード一行で自動化するモダンな手法から、実際の学習実行にいたる一連の流れを、完全ハンズオン形式で一歩ずつ丁寧に解説します。
事前準備:学習用データセットの取得と確認
機械学習の第一歩は、データの理解から始まります。
今回は、銀行の電話勧誘キャンペーンの結果をまとめた「UCI Bank Marketing Dataset」を使用し、顧客が定期預金に申し込むかどうかを予測するモデルを作成します。
ノートブックインスタンスの起動と環境確認
まずはAmazon SageMakerのコンソールから、作業の拠点となるノートブックインスタンスを作成します。
同時に必要な権限(IAMロール)もその場で作成してしまいましょう。
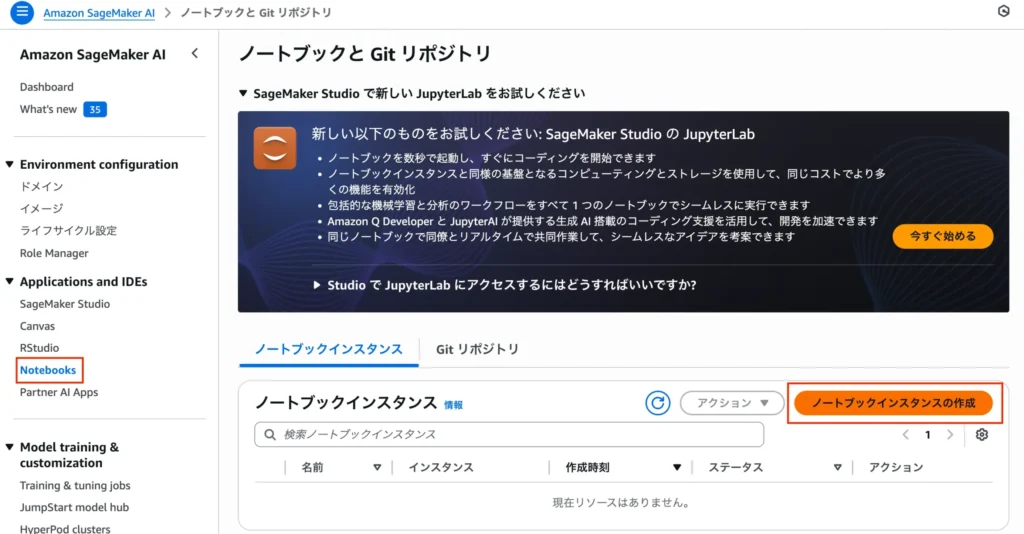
1.ノートブックインスタンスの作成画面へ
SageMaker AIコンソールの左メニューから [Notebooks] > [ノートブックインスタンス]タブにある[ノートブックインスタンスの作成] をクリックします。
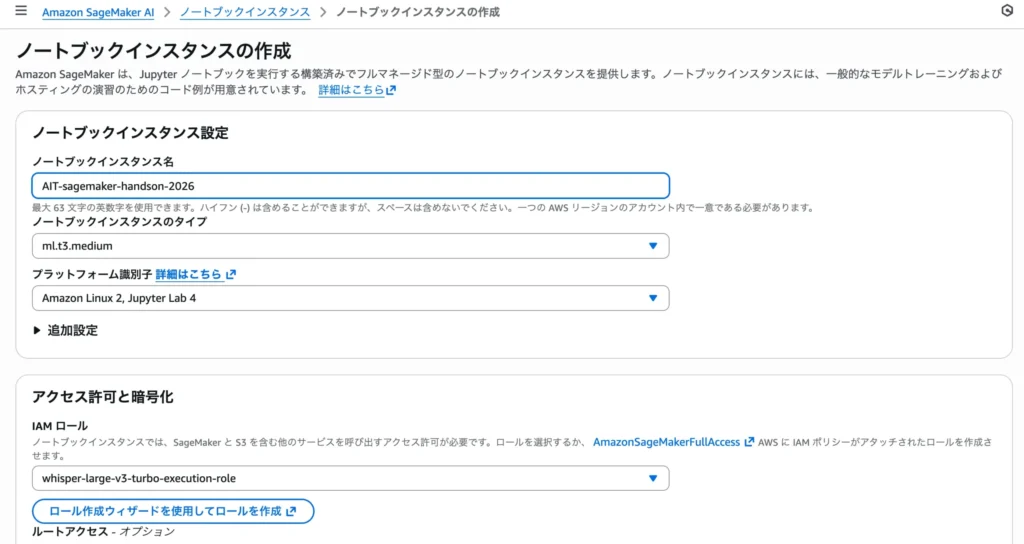
2.基本設定
名前:任意の名前(一意であること)を入力します。
インスタンスタイプ:コスト効率の良い「ml.t3.medium」を選択します。
プラットフォーム識別子:最新の環境である Amazon Linux 2, Jupyter Lab 4 を選択します。
3.IAMロールの作成
[アクセス権限と暗号化] セクションにある「ロール作成ウィザードを使用してロールを作成」を押下します。
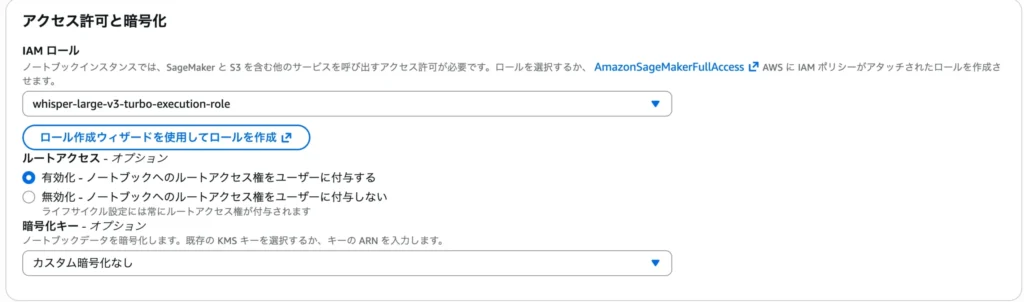
4.ロール情報を入力
ロール名のサフィックス:任意のロール名を入力する。
ペルソナ:[MLオペレーション]を選択する。
その他デフォルト設定でロールを作成します。
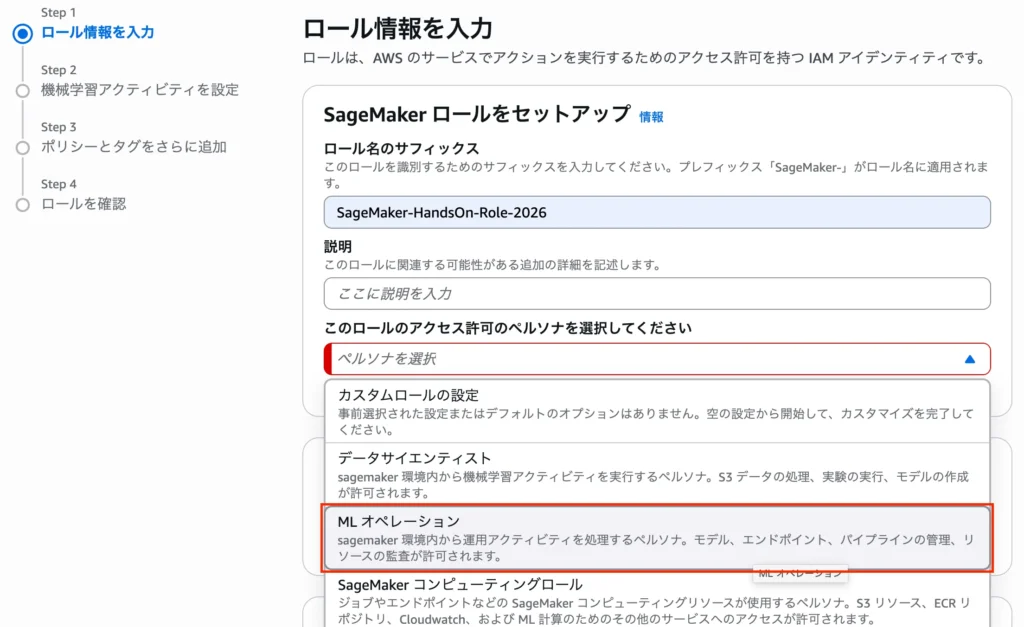
5.ノートブックインスタンスの作成
作成したS3へのアクセス権限を持つIAMロールを割り当て[ノートブックインスタンスの作成]を押下します。
インスタンスのステータスが InService になったら、[JupyterLab を開く] をクリックして作業を開始しましょう。
Step 1:データのダウンロード(UCI Bank Marketing Dataset)
ノートブックインスタンスが起動したら「JupyterLabを開く」をクリックして、新しいノートブック(Python 3)を立ち上げましょう。
最初の作業は、学習の素材となるデータセットの取得です。
今回は、機械学習のベンチマークとして有名な「UCI Bank Marketing Dataset」を使用します。
これは銀行の電話勧誘キャンペーンの結果を記録したデータで、顧客の属性から定期預金に申し込むかどうかを予測するモデルの作成に適しています。
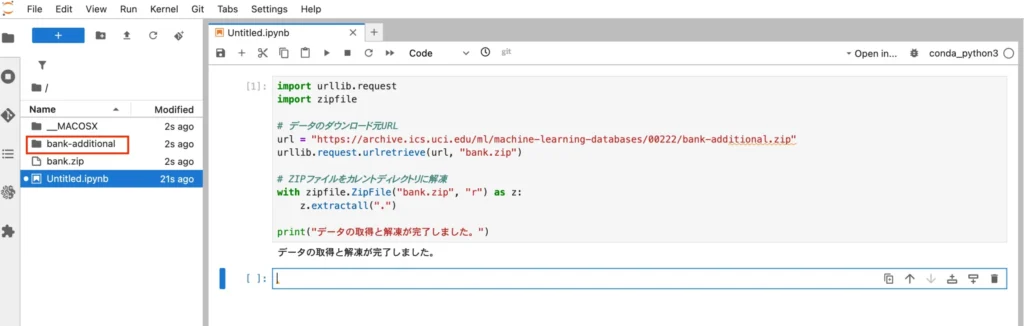
以下のコードを実行して、外部サーバーから直接インスタンスのローカルストレージ(EBSボリューム)へデータをダウンロードし、解凍します。
import urllib.request
import zipfile
# データのダウンロード元URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip"
urllib.request.urlretrieve(url, "bank.zip")
# ZIPファイルをカレントディレクトリに解凍
with zipfile.ZipFile("bank.zip", "r") as z:
z.extractall(".")
print("データの取得と解凍が完了しました。")この操作はAWS内部の高速なネットワークを通じて行われるため、手元のPCの帯域を消費しません。
ダウンロードされたデータは、インスタンスにアタッチされた5GB(初期設定)のEBSに保存されます。
ファイルブラウザに bank-additional というフォルダが現れたことを確認してください。
Step 2:データのロードと中身の把握
次に、解凍されたCSVファイルをPythonのデータ分析ライブラリ「Pandas」を使って読み込みます。
インフラエンジニアにとってのログ解析と同じように、まずはデータがどんな形式で、どんな項目を含んでいるのかを可視化して把握することが不可欠です。
import pandas as pd
# CSVの読み込み。区切り文字がセミコロン(;)である点に注意
df = pd.read_csv("./bank-additional/bank-additional-full.csv", sep=";")
# データの先頭5行を表示
pd.set_option('display.max_columns', 500) # すべての列を表示するための設定
df.head()表示されたデータフレームを確認すると、age(年齢)job(職業)marital(既婚・未婚)といった顧客属性が並んでいます。
一番右端にある y という列が、今回AIに予測させたい答え(ターゲット)です。
yes なら申し込みあり、no なら申し込みなしを意味します。
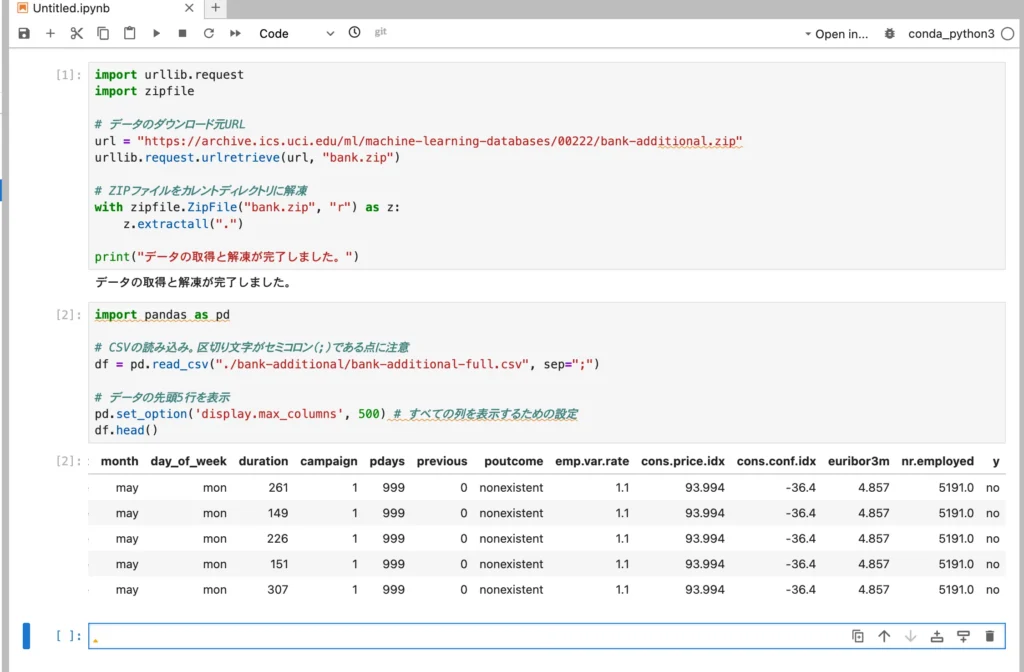
SageMaker(XGBoost)形式へのデータ整形
ここが本ハンズオンの隠れた重要ポイントです。
SageMakerに標準で用意されている組み込みアルゴリズム(今回はXGBoost)を利用する場合、データの形式について厳格なお作法を守らなければなりません。
このお作法を無視すると、後の学習ジョブ実行時に必ずエラーに直面します。
主なルールは以下の2点です。
1.数値データ化(One-hot Encoding)
アルゴリズムは文字列を理解できません。
jobやmaritalなどの文字列データを、0と1の数値に変換する必要があります。
2.ターゲット列を先頭(1列目)に配置
これが最もつまずきやすい点です。
SageMakerの組み込みXGBoostは、CSVの1列目を正解ラベル(ターゲット)として読み込むという仕様になっています。
以下のコードで、この「お作法」に則った最終的な学習用データを作成します。
# 1. 文字列データを数値(0/1)に一括変換
df_with_dummies = pd.get_dummies(df)
# 2. ターゲット変数(y_yes)をリストの先頭に移動させる
cols = df_with_dummies.columns.tolist()
cols.insert(0, cols.pop(cols.index('y_yes')))
df_final = df_with_dummies[cols]
# 3. 冗長な列(y_no)を削除して整形完了
df_final = df_final.drop(['y_no'], axis=1)
print(f"整形完了後のデータ形状: {df_final.shape}")
df_final.head()データが整形されたことを確認しましょう。
今回、あえてこの整形を忘れた状態で学習を投げるとどうなるかというトラブルシューティングも後ほど紹介します。
インフラ屋としては、こうした仕様による制約を理解しておくことが、スムーズなデバッグへの近道となります。
実践:データをS3バケットへアップロードする
機械学習のモデル学習では、計算リソース(サーバー)とストレージを分離するのがクラウドネイティブな流儀です。
ノートブックインスタンス内に保存したデータは、そのままでは学習ジョブから参照できません。
そこで、スケーラビリティと耐久性に優れたS3を「データ共有のハブ」として活用します。
Step 4:SageMakerセッションとS3バケットの準備
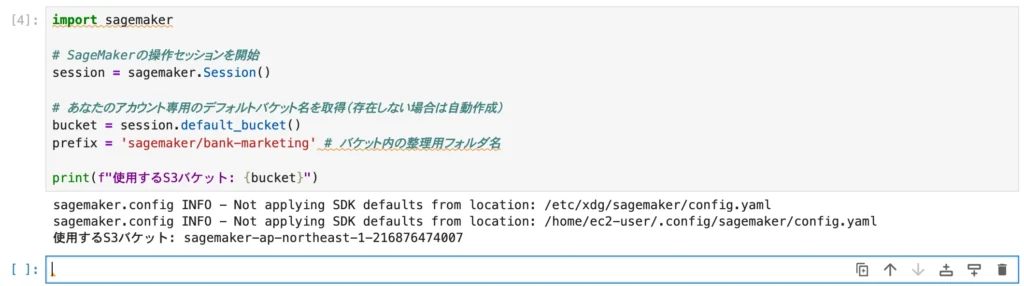
まず、PythonコードからSageMakerの各種リソースを操作するための「セッション」を開始します。
ここで特筆すべきは、S3バケットをわざわざ手動で作成する必要がない点です。
import sagemaker
# SageMakerの操作セッションを開始
session = sagemaker.Session()
# あなたのアカウント専用のデフォルトバケット名を取得(存在しない場合は自動作成)
bucket = session.default_bucket()
prefix = 'sagemaker/bank-marketing' # バケット内の整理用フォルダ名
print(f"使用するS3バケット: {bucket}")session.default_bucket() を実行すると、sagemaker-[リージョン名]-[アカウントID] という命名規則でバケットが自動的にプロビジョニングされます。
インフラの準備すらコード一行で完結させる、まさにIaC(Infrastructure as Code)の利便性を象徴する機能です。
Step 5:Python SDK(upload_data)による転送
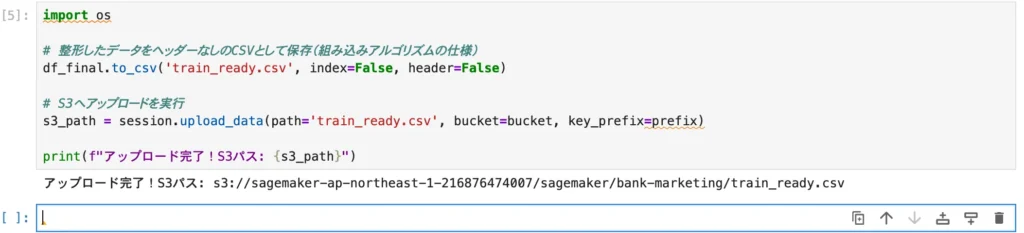
次に、整形済みのデータをCSV形式で出力し、SageMaker SDKのメソッドを使ってS3へ一気にアップロードします。
import os
# 整形したデータをヘッダーなしのCSVとして保存(組み込みアルゴリズムの仕様)
df_final.to_csv('train_ready.csv', index=False, header=False)
# S3へアップロードを実行
s3_path = session.upload_data(path='train_ready.csv', bucket=bucket, key_prefix=prefix)
print(f"アップロード完了!S3パス: {s3_path}")このコマンドは、ノートブックインスタンスにアタッチされたEBSボリュームから、AWS内部の高速ネットワークを通ってS3へデータを転送します。
手持ちのPCを経由しないため、数GBクラスの大容量データであっても非常に高速かつセキュアに処理が完了するのがメリットです。
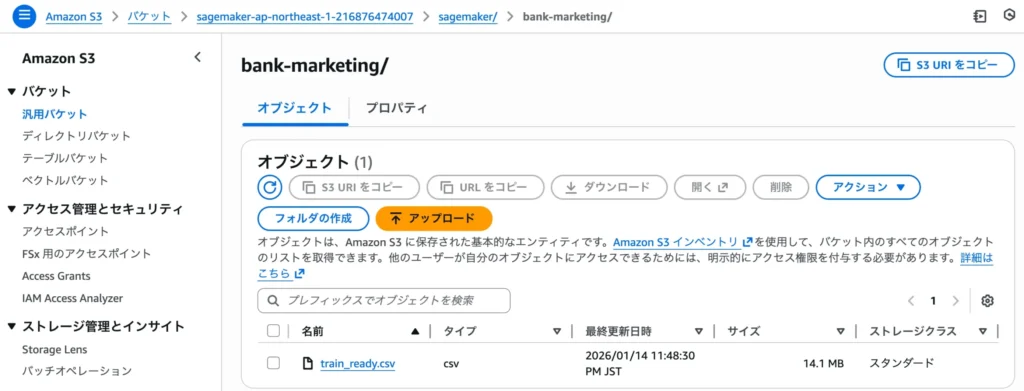
Step 6:S3コンソールでのアップロード確認
コード上で「完了」と表示されたら、最後はインフラエンジニアらしく実体を自分の目で確認しましょう。
1.AWSマネジメントコンソールから [S3] を開きます。
2.sagemaker-ap-northeast-1-… という名前のバケットを探し、クリックします。
3.sagemaker/bank-marketing/ という階層を辿り、その中に train_ready.csv が保存されていることを確認してください。
設定:学習アルゴリズムとリソースの定義
SageMakerの最大の特徴は、計算リソースが「使い捨て」である点です。
学習時だけ高性能なインスタンスをプロビジョニングし、終われば即座に開放する。
この柔軟な運用を実現するための設定を見ていきましょう。
Step 7:組み込みアルゴリズム(XGBoost)コンテナの取得
SageMakerでは、学習アルゴリズムがDockerコンテナイメージとして管理されています。
自分で環境を構築することなく、AWSが最適化した信頼性の高いイメージを呼び出すだけで準備が完了します。
今回は、構造化データの分類に非常に強力な「XGBoost」を使用します。
# リージョンに基づいたXGBoostのコンテナURIを取得
container = sagemaker.image_uris.retrieve("xgboost", session.boto_region_name, "1.5-1")
print(f"使用するコンテナイメージ: {container}")特定のライブラリのバージョンが合わないといった環境依存のトラブルは、コンテナ化によって完全に解消されています。
インフラ担当としては、パッケージ管理の苦労から解放されるのが最大のメリットです。

Step 8:Estimatorによる計算インスタンスの設定
次に、学習ジョブの「設計図」となる Estimator(エスティメーター) オブジェクトを作成します。
ここで、先ほど作成したIAMロールや、実際に計算を行うEC2インスタンスのスペックを指定します。
import sagemaker
# 1. SageMakerの実行ロール(IAMロール)の取得 (Step 8で利用)
role = sagemaker.get_execution_role()
print(f"現在の実行ロール: {role}")
# 2. 組み込みアルゴリズム(XGBoost)コンテナの取得
session = sagemaker.Session()
container = sagemaker.image_uris.retrieve("xgboost", session.boto_region_name, "1.5-1")
# 3. Estimatorによる計算インスタンスの設定 (Step 8)
# ここで「どの計算機を」「どの権限で」動かすかの設計図(Estimator)を作成します
xgb = sagemaker.estimator.Estimator(
image_uri=container,
role=role, # 上で取得したroleをここで渡します
instance_count=1, # 学習に使用するインスタンス数
instance_type='ml.m5.large', # 計算用インスタンスのタイプ
output_path=f's3://{session.default_bucket()}/sagemaker/bank-marketing/output',
sagemaker_session=session
)
print("Estimator(計算リソース)の設定が完了しました。")今回のデータセット規模であれば、高価なGPUインスタンスは不要です。
汎用的な m5 シリーズを選択することで、十分な計算速度を確保しつつコストを最小限に抑えます。
大規模なデータであれば複数台での分散学習も可能ですが、今回は1台で十分です。

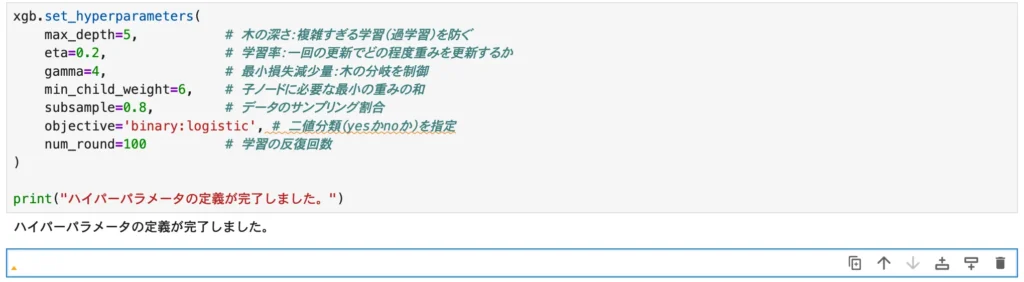
Step 9:ハイパーパラメータの定義と調整ポイント
AIモデルには、学習の「クセ」を調整するためのつまみ(ハイパーパラメータ)が存在します。
アルゴリズムがデータをどのように解釈するかを、ここで指示します。
xgb.set_hyperparameters(
max_depth=5, # 木の深さ:複雑すぎる学習(過学習)を防ぐ
eta=0.2, # 学習率:一回の更新でどの程度重みを更新するか
gamma=4, # 最小損失減少量:木の分岐を制御
min_child_weight=6, # 子ノードに必要な最小の重みの和
subsample=0.8, # データのサンプリング割合
objective='binary:logistic', # 二値分類(yesかnoか)を指定
num_round=100 # 学習の反復回数
)
print("ハイパーパラメータの定義が完了しました。")初回は標準的な値で進めるのが定石です。
インフラエンジニアとしては、これらの値を変更することで「計算負荷」や「学習時間」が変動することを覚えておくと、リソース計画を立てやすくなります。
実行:学習ジョブの開始とモニタリング
設定が完了したら、いよいよ学習を実行します。
SageMakerではfitメソッドを呼び出すことで、裏側で計算リソースのプロビジョニングから学習、リソースの解放までが自動で行われます。
Step 10:fitメソッドによる学習ジョブのキック
以下のコードを実行して、学習ジョブを開始しましょう。
ここでは整形前のデータを用いて、意図的に失敗を引き起こします。
import pandas as pd
import sagemaker
import os
# セッション情報の再取得
session = sagemaker.Session()
bucket = session.default_bucket()
prefix = 'sagemaker/bank-marketing'
# --- ここから失敗データの作成 ---
# 1. 元データを再読み込み
df_orig = pd.read_csv("./bank-additional/bank-additional-full.csv", sep=";")
# 2. 文字列を数値化(One-Hot Encoding)だけ行う
# ※重要:ここでは列の並べ替え(ターゲットを先頭へ移動)を行いません!
df_wrong_shape = pd.get_dummies(df_orig)
# 確認用:先頭の列がターゲット(0か1)ではなく、'age'などの特徴量になっていることを確認
print("意図的に間違ったデータ形式の先頭列名:", df_wrong_shape.columns[0])
# 3. 間違った形式のままCSVファイル化(ヘッダーなし)
wrong_csv_name = 'train_wrong_shape.csv'
df_wrong_shape.to_csv(wrong_csv_name, index=False, header=False)
# 4. S3へアップロード
s3_path_wrong = session.upload_data(path=wrong_csv_name, bucket=bucket, key_prefix=prefix)
print(f"失敗用データをS3にアップロードしました: {s3_path_wrong}")
# 5. 学習ジョブの入力として設定
train_input_wrong = sagemaker.inputs.TrainingInput(
s3_data=s3_path_wrong,
content_type='csv'
)
# --- 学習の実行(エラー発生を期待)---
print("\n--- あえて失敗させる学習ジョブを開始します。数分後にエラーが出るはずです ---")
# 以前定義したestimator 'xgb' を再利用してfitを呼び出す
xgb.fit({'train': train_input_wrong})このコマンドを叩いた瞬間、AWSの裏側ではml.m5.largeインスタンスの確保、Dockerコンテナのデプロイ、S3からのデータロードが開始されます。
ログに Starting と表示されている間は、このプロビジョニングが行われています。
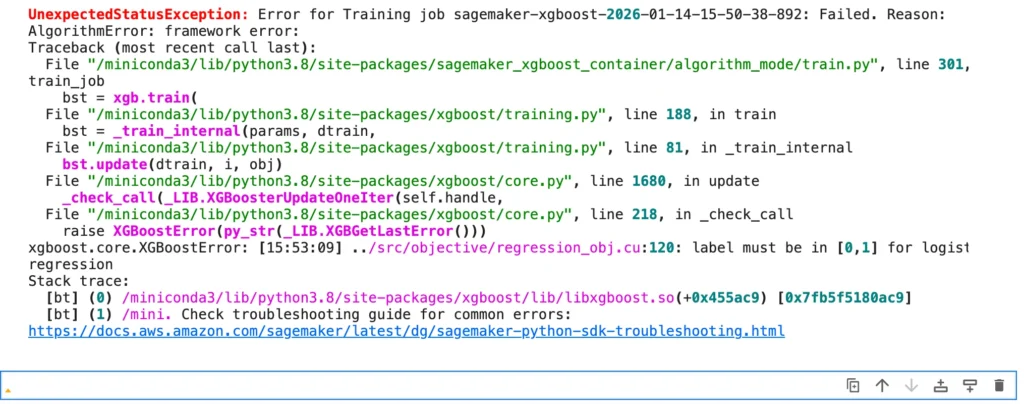
【トラブル対策】「label must be in [0,1]」エラーの解消手順
数分待つと、勢いよく流れていたログが突然止まり、画面に赤い文字でエラーが表示されるはずです。
あるいは、AWSコンソールのステータスが 「Failed」 に変わります。
【よくあるエラーメッセージ】
AlgorithmError: framework error: … label must be in [0,1] …
デバッグの手順を確認しましょう。
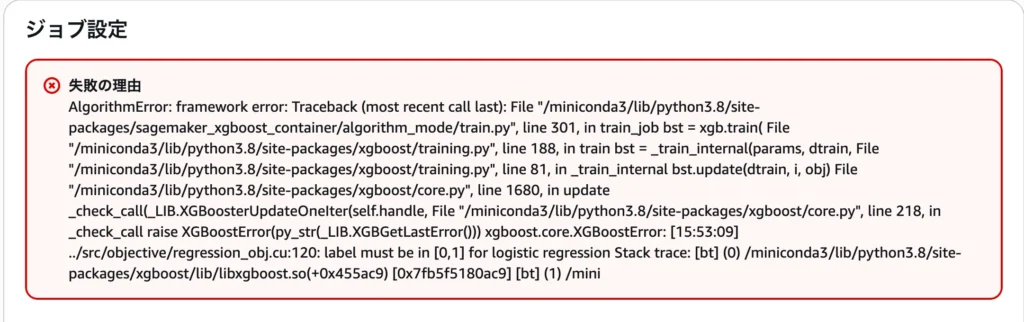
1.コンソールを確認
SageMaker左メニューModel training & customization> Training & tuning jobs一覧から、失敗したジョブをクリックします。
2.失敗の理由(Failure reason)
画面上部の「失敗の理由」欄を確認します。ここにエラーの核心が書かれています。
3.原因の特定
XGBoostの組み込みアルゴリズムは「1列目が正解ラベル(0か1)」であることを期待しています。
もしデータの1列目に「年齢(age)」などの数値が入っていると、「ラベルは0か1であるべきだ!」と怒られてしまうのです。
データの再整形と学習ジョブの再実行
原因が列配置と判明したら、仕様「1列目がターゲット」に合わせデータを修正します。
Pandasで並べ替えとヘッダー除去を行いS3へ再送します。
インフラのスキーマ修正同様、正確な整形が成功の鍵です。
fitの再実行で学習が開始されます。
失敗から仕様を学び、即リカバリするサイクルこそハンズオンの醍醐味ですね。
# ターゲット変数(y_yes)を先頭(0列目)に移動
cols = df_final.columns.tolist()
cols.insert(0, cols.pop(cols.index('y_yes')))
df_fixed = df_final[cols]
# ヘッダーなしCSVとして保存し、S3に再送
df_fixed.to_csv('train_correct.csv', index=False, header=False)
s3_path_fixed = session.upload_data(path='train_correct.csv', bucket=bucket, key_prefix=prefix)
# 修正されたパスで再学習を開始
xgb.fit({'train': sagemaker.inputs.TrainingInput(s3_path_fixed, content_type='csv')})Step 11:CloudWatch Logsでの進捗確認
SageMakerの学習ジョブが開始されると、JupyterLabのセル出力にはリアルタイムでログが表示されます。
ロググループ名:/aws/sagemaker/TrainingJobs
これは裏側でAmazon CloudWatch Logsと連携し、インスタンス内部の挙動を可視化しているものです。
ログには、データの読み込みから、アルゴリズムによる各ステップの進捗(train-loglossなど)が詳細に記録されます。
Step 12:マネジメントコンソールでのステータス監視
学習が完了したら、AWSマネジメントコンソールの「トレーニングジョブ」画面を確認します。
ステータスが緑色のCompletedに変わっていれば成功です。
ここでインフラエンジニアとして注目すべきは「請求可能な時間」です。
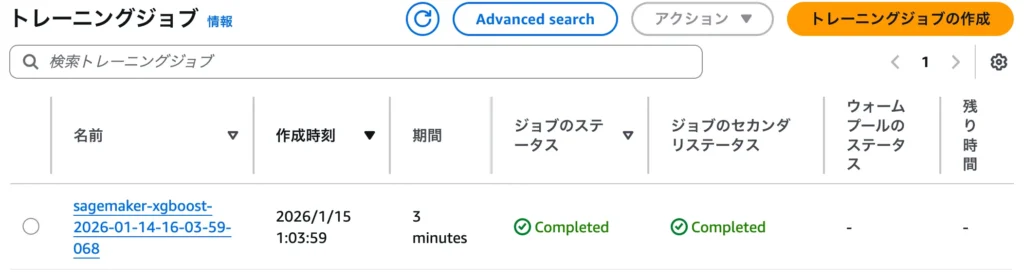
詳細を確認すると、今回の例では130秒と記録されていました。
SageMakerは、インスタンスの起動や設定にかかるオーバーヘッド時間を除き、純粋にアルゴリズムが動いた秒単位の時間のみを課金対象とします。
この必要な時だけ立ち上がり、最小限のコストで済む特性は、大規模な環境運用において非常に強力な武器となります。
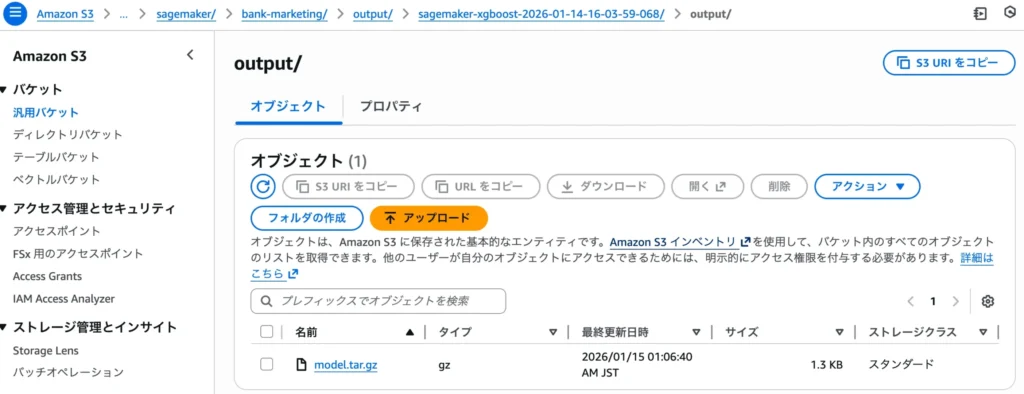
Step 13:モデル成果物(model.tar.gz)の生成確認
学習ジョブが完了すると、成果物である「モデル」がS3バケットへ自動的に保存されます。
S3コンソールのバケット一覧から、指定した出力パス(output/)を辿ってみましょう。
ジョブ名のフォルダ階層の中に、「model.tar.gz」というファイルが生成されているはずです。
これこそがAIの脳そのものであり、XGBoostが学習した成果が凝縮されたバイナリファイルです。
インフラエンジニアとしては、このファイルが指定場所に配置されたことを確認して初めて、学習パイプラインが完結したと言えます。
この成果物は、後のデプロイ工程で推論エンドポイントを立てる際の核となります。
完了:後片付けとコスト管理の徹底
クラウドを使いこなすエンジニアにとって、「リソースの停止」は構築と同じくらい重要な工程です。
検証が終わった後に無駄な課金を発生させないよう、以下の手順で確実に後片付けを行いましょう。
Step 14:S3上のモデルパスの保存
学習が完了したら、生成されたモデルの「居場所」を正確に把握しておく必要があります。
SageMakerでは、Estimatorオブジェクトのプロパティから、S3上のモデルパス(URI)をプログラムで直接取得できます。
# 生成されたモデル成果物(model.tar.gz)のS3パスを表示
print(f"モデルの保存先: {xgb.model_data}")このパスは、後続の「推論(デプロイ)」フェーズで、AIモデルをAPIサーバーとして立ち上げる際に指定する情報です。
インフラ構成管理の観点からは、このURIをパラメータストアや環境変数に控えておくことで、デプロイ作業の自動化(CI/CD)が容易になります。
計算インスタンスが消えても、S3上のこのファイルさえあれば、いつでもAIの脳を再現できることを覚えておきましょう。
Step 15:【重要】ノートブックインスタンスの停止
検証作業が一段落したら、最も重要な「コスト管理」の手順を忘れずに行います。
ノートブックインスタンスは、JupyterLabのタブを閉じただけでは計算料金が発生し続けるため、手動での停止操作が必須です。
AWSコンソールの「ノートブックインスタンス」一覧から、対象のインスタンスを選択し、[アクション] > [停止] を実行してください。
ステータスが Stopped になれば、EC2ベースのコンピューティング料金は停止します。
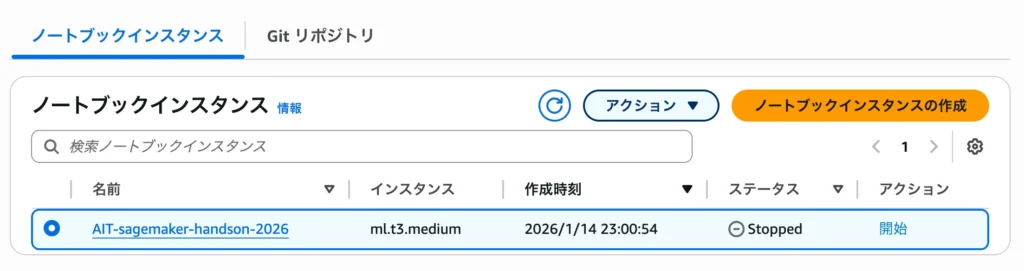
インスタンスを削除せず停止に留めることで、作成したコードや中間データを保持したまま、ストレージ(EBS)のわずかな料金のみで維持できます。
※完全に課金を止めたい場合は削除して下さい。
インフラ担当として、「構築・実行・停止」をワンセットの習慣にすることが、クラウド活用の鉄則です。
まとめ
本記事では、インフラエンジニアの視点でSageMakerでの学習フローを体験しました。サーバー管理から解放され、秒単位課金や自動リソース破棄といったマネージドサービスの恩恵を実感できたはずです。
特に「1列目ルール」のような特有の仕様への対処は、実務でのトラブル回避に直結します。成果物であるモデルはS3に安全に保存されています。
最後は必ずノートブックを停止し、コストを最適化して次のステップへ備えましょう。