

「Azure Databricksって何?」「難しそうで手が出せない…」そんな悩みはありませんか?
クラウドやデータ分析に興味があるエンジニア初心者の方なら、誰もが一度は感じる疑問です。
本記事では、Azure Databricksの基本から活用法、導入手順までをわかりやすく解説します。データ分析や機械学習に強いAzure Databricksの魅力をやさしく紹介するので、学習の第一歩に最適です。
これからスキルを伸ばしたい方は、ぜひ最後まで読んで理解を深めましょう。
1、Azure Databricksとは?わかりやすく解説
Azure Databricksは、Microsoft Azure上で利用できるクラウドベースのデータ分析・AIプラットフォームです。Apache Sparkをベースにした高速かつスケーラブルな分析エンジンを搭載し、大量のデータ処理や機械学習モデルの構築が可能です。
より詳しく言うと、Azure Databricksはただの「分析ツール」ではなく、データ分析・AI開発・データエンジニアリングを一つの環境で行えるクラウドベースの統合分析基盤です。
Azure Databricks = Azureのセキュリティ + Apache Spark
Databricksの心臓部には、Apache Sparkという超高速な分散処理エンジンが使われています。これをAzureが提供するクラウドのセキュリティ・運用のしやすさと組み合わせたのが、Azure Databricksです。
Apache Sparkとは?
Apache Sparkは、大量データを超高速で処理できるオープンソースの分散処理エンジンです。ビッグデータ分析やAI開発、リアルタイム処理にも使われており、今や世界中のデータ基盤で活躍しています。
Apache Sparkを利用するメリットは以下のとおりです。
- 大量のデータをまとめて処理(バッチ処理)
- リアルタイムに動くデータを処理(ストリーミング処理)
- AIや機械学習の土台作り(膨大なデータを使って予測モデルを作るときに役立つ)
- SQLのようにデータを簡単に扱える
- 可視化・共有も容易
Azure Databricksでできること5選!
Azure Databricksは、データ分析・AI開発のためのクラウドプラットフォームです。
裏側ではApache Sparkが動いていますが、もっと使いやすく・見やすく・協力しやすくなっているのが特徴です。
① データの収集・加工(ETL処理)
Azure Databricksでは、さまざまなデータソース(CSV, Excel, Azure Storage, SQL DBなど)からデータを取り込み、加工・変換できます。
例:
- 売上データをクレンジングして、集計表を作る
- 複数のデータを結合して一つの分析用データにする
② ノートブックでの分析・プログラミング
Jupyterライクな「ノートブック」を使って、PythonやSQLでコードを書きながらデータ分析や可視化ができます。コードと結果が同じ画面に出るので、直感的で分かりやすいです。
例:
- 売上トレンドをグラフで可視化
- SQLでトップ10の商品を抽出
③ AI・機械学習モデルの開発と実験
Azure Databricksには**機械学習ライブラリ(MLlibなど)**が標準搭載されています。さらに、Azure Machine Learning や AutoML と連携して、モデルの訓練・評価・管理もクラウド上で完結できます。
例:
- 顧客が離れそうかを予測するモデルを作成
- 売上予測モデルをチームで共同開発
④ スケーラブルなSparkクラスターで高速処理
Azure Databricksでは、クラウドのリソース(Sparkクラスター)を自動で立ち上げ・停止できるため、必要なときだけ大きな計算力を使えます。コスト効率もバッチリ。
例:
- 数十億件のログを1時間で集計
- クラスタは使い終わったら自動停止で無駄なし
⑤ チームでの共同作業・共有がしやすい
ノートブックは複数人でリアルタイム編集でき、コメント機能やバージョン管理も充実。
ビジネス担当、分析担当、エンジニアが同じ場所で作業できます。
例:
- ノートブックをPDFやHTMLで共有
- 分析結果にコメントをつけて議論
3、Azure Databricksのアーキテクチャ
コントロールプレーンとデータプレーン
Azure Databricksは「コントロールプレーン(管理領域)」と「データプレーン(実行環境)」の二層構造を採用しています。コントロールプレーンはDatabricks社が管理し、ワークスペースやノートブックなどを管理します。一方、データプレーンはユーザーのAzure環境内にあり、データの安全性が確保されています。
クラスターによる処理の分散化
Azure Databricksでは、クラスター(仮想マシンの集合体)を用いてデータ処理を分散化します。自動スケーリングやスケジューリング機能も搭載されており、効率的かつ柔軟なリソース管理が可能です。
4、Azure Databricksの利用料金
Azure Databricksの料金は、単純な月額定額制ではなく、以下の3つの軸で構成されています。
- コンピュートの種類(ワークロードタイプ)
- プランレベル(Standard / Premiumなど)
- 支払いオプション(従量課金 / 予約インスタンス / スポットなど)
この3つの組み合わせによって、実際にかかるコストが大きく変わります。
コンピュートの種類
Databricksでは、どんな方法でワークロード(作業)を実行するかによって、「コンピュートタイプ(実行環境の種類)」を選びます。主に次の3つがあります。
All-Purpose Compute(オールパーパス)
ノートブックでインタラクティブに作業するユーザー向け。データの探索や試行錯誤がしやすく、最も汎用的ですが、料金は少し高め。
初学者や分析チームの共同作業にはこれが最適。
Jobs Compute(ジョブコンピュート)
バッチ処理やスケジュール実行など、自動化されたジョブを効率的に実行するのに適した選択肢。コスト効率がよく、業務システム向け。
毎日集計を回すようなビジネス処理におすすめ。
Jobs Light Compute(ライト版)
さらに軽量なジョブ専用。最小限の機能に絞った設計で、より低コスト。小規模な定期実行処理などに向いています。
コストを最小限に抑えたい場合はこちら。
Azure Databricksのプラン
Standardプラン
Standardプランは、Azure Databricksを初めて使う人や、スモールスタートを考えている企業に最適なベーシックプランです。
このプランでは、以下のような基本機能が利用できます:
- Apache Sparkを活用した高速な分散処理
- ノートブック(Jupyter風の操作画面)による対話的な分析
- PythonやSQLを使ったデータ処理や可視化
- Databricks Delta(高性能なテーブル形式)
- MLflow(機械学習モデルの管理ツール)
- オートスケーリング機能(リソースを自動調整)
✅「とりあえずデータ分析環境を整えたい」「小規模で使い始めたい」という方におすすめです。
【2】Premiumプラン
Premiumプランは、Standardプランのすべての機能に加え、より高度なセキュリティ・アクセス管理・運用制御の機能を提供する上位プランです。
特に注目すべき追加機能は次の通り:
- ノートブック・ジョブ・クラスターごとのアクセス制御
- 監査ログの取得(誰がいつ何をしたかを追跡可能)
- Azure Active Directory(Microsoft Entra ID)との統合による認証強化
- ワークスペースごとのガバナンス設定(クォータやポリシー)
✅「複数人のチームで使いたい」「アクセス制御や監査が必要」「企業内ポリシーに準拠したい」といったケースに最適です。
5、Azure Databricksに似ているAzureサービスとの違い
Azure Synapse Analyticsとの違い
Azure Synapseは、データウェアハウスに特化したサービスで、SQLベースのクエリが得意です。一方、Azure DatabricksはApache Sparkによる分散処理やAIモデル開発が強みです。両者は競合というより、補完関係にあるといえます。
HDInsightとの違い
Azure HDInsightもApache Sparkをサポートしていますが、Azure Databricksの方がセットアップが簡単で、ノートブックやUIの使いやすさが優れています。また、Azure Databricksは開発スピードが早く、最新のSparkバージョンにもすぐ対応するという利点があります。
Azure Machine Learningとの違い
Azure Machine Learningは、機械学習のライフサイクル全体を管理するためのサービスです。Azure Databricksは、その中でデータ処理やモデルトレーニングを担う部分を強化するポジションにあります。両者を連携させることで、より高度なMLパイプラインの構築が可能になります。
6、Azure Databricksをデプロイする手順を解説
Azure Databricks は、Apache Spark ベースの高速な分析プラットフォームであり、AI・機械学習・ビッグデータ分析を加速する強力なサービスです。ここからは、Azure Databricks ワークスペースの作成方法を詳しく解説します。
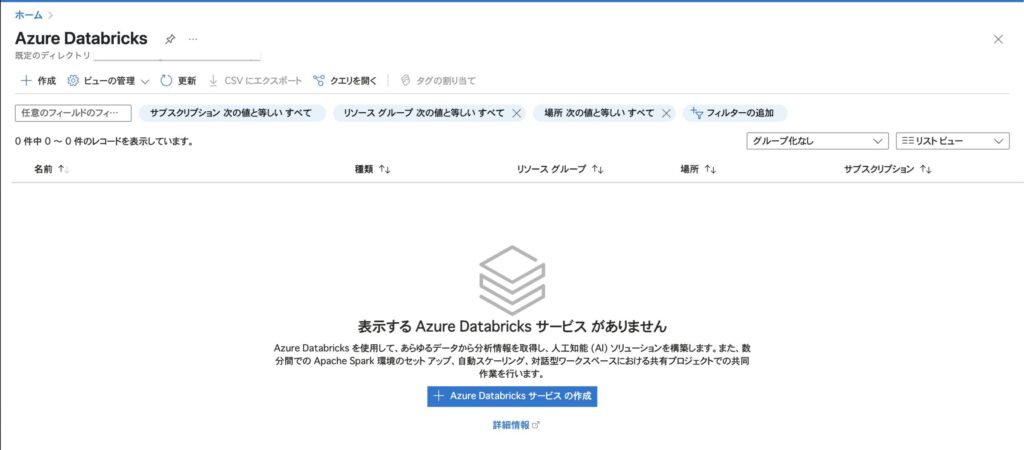
ステップ1:Azure ポータルにサインインし、Databricks を開く
まずは Azure ポータル にアクセスしてサインインします。
検索バーで「Databricks」と入力し、「Azure Databricks」サービスを開きましょう。
この時点ではまだワークスペースが存在しないため、「表示する Azure Databricks サービスがありません」と表示されるはずです。
ステップ2:Databricks ワークスペースの作成を開始
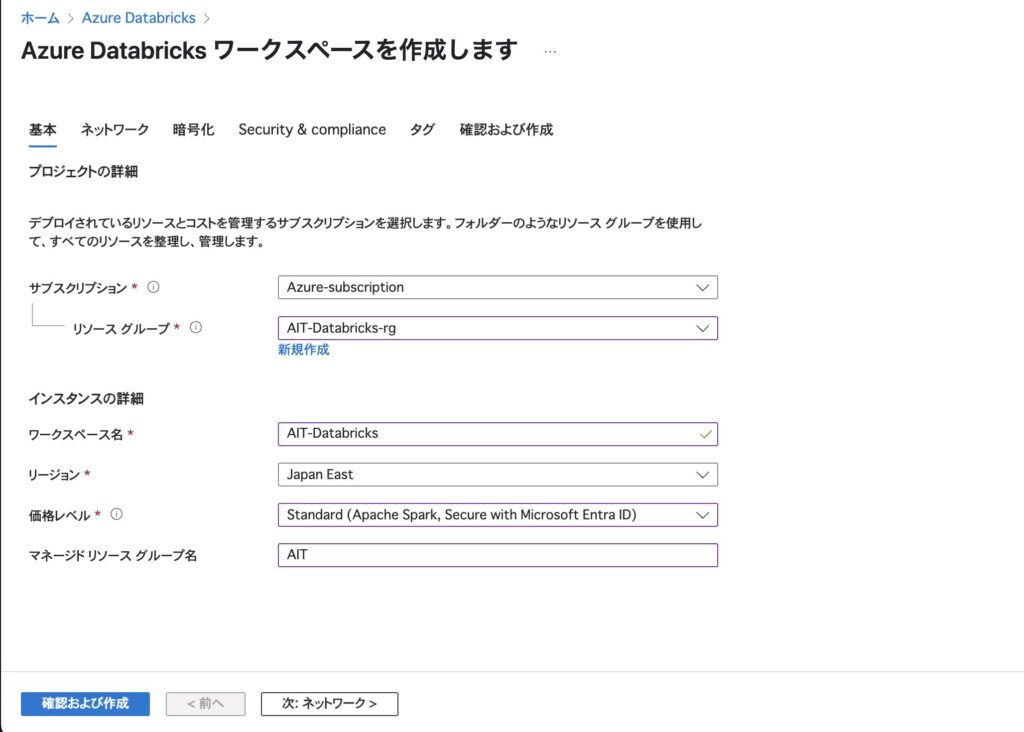
右下の 「+ Azure Databricks サービスの作成」 をクリックして、作成ウィザードを開始します。
基本設定の入力を行います。
- サブスクリプション:利用する Azure サブスクリプションを選択
- リソースグループ:既存のグループを選択するか、「新規作成」します
- ワークスペース名:任意の名前を入力(例:
AIT-Databricks) - リージョン:近い地域を選びましょう(例:
Japan East) - 価格レベル:今回は
Standardを選択
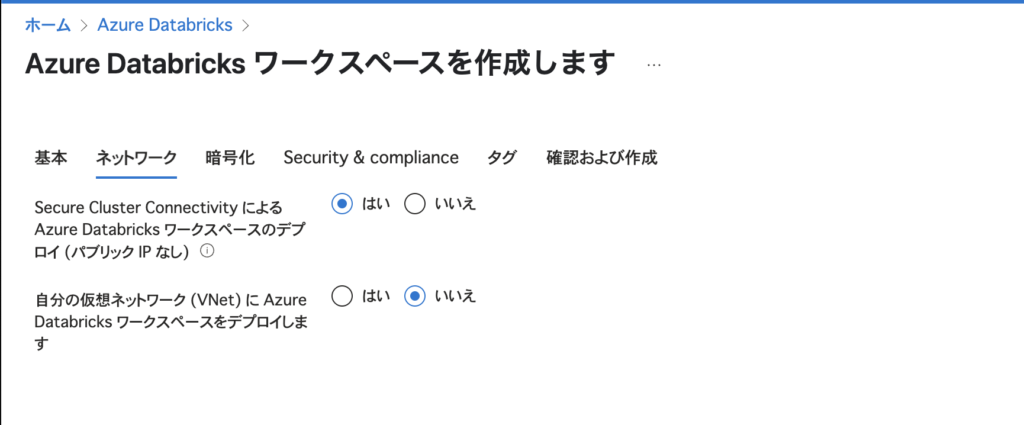
ステップ3:ネットワーク設定
- Secure Cluster Connectivity(セキュアクラスター接続):
はいを推奨(セキュリティ強化) - VNet デプロイ:
いいえのままで問題ありません(初回はVNet不要)
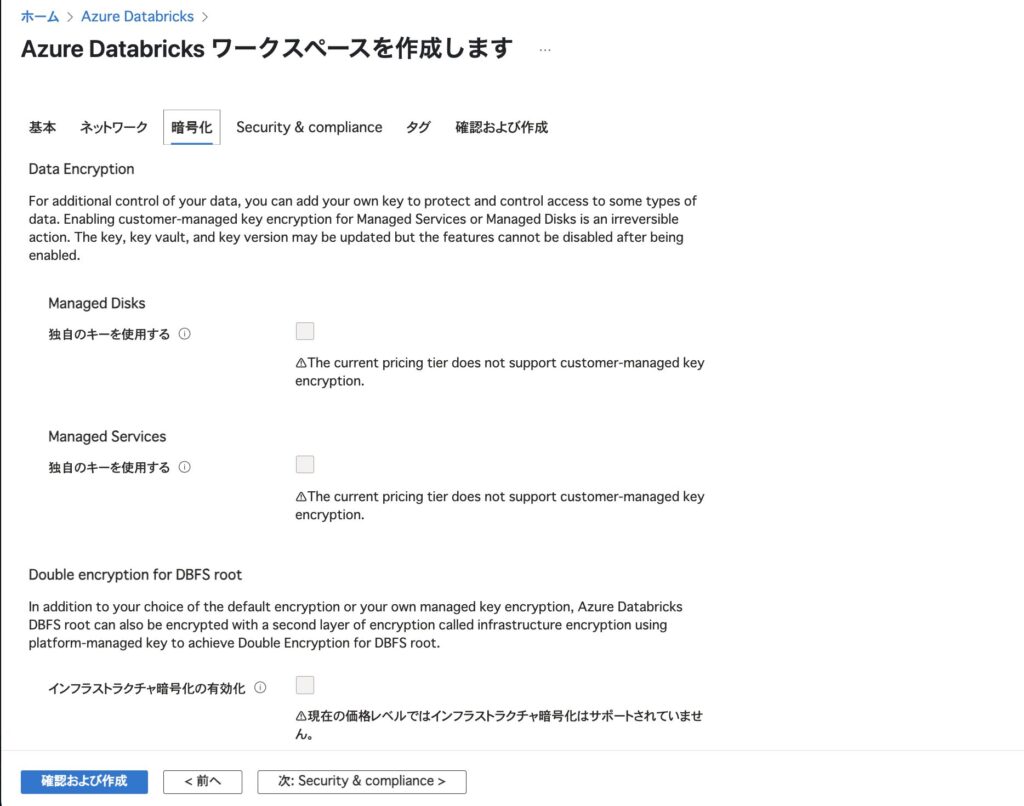
ステップ4:暗号化オプション(任意)
デフォルトではすべて無効化されており、Standardプランでは利用できないオプションが多いです。
とくに理由がなければこのまま「次へ」で進みましょう。
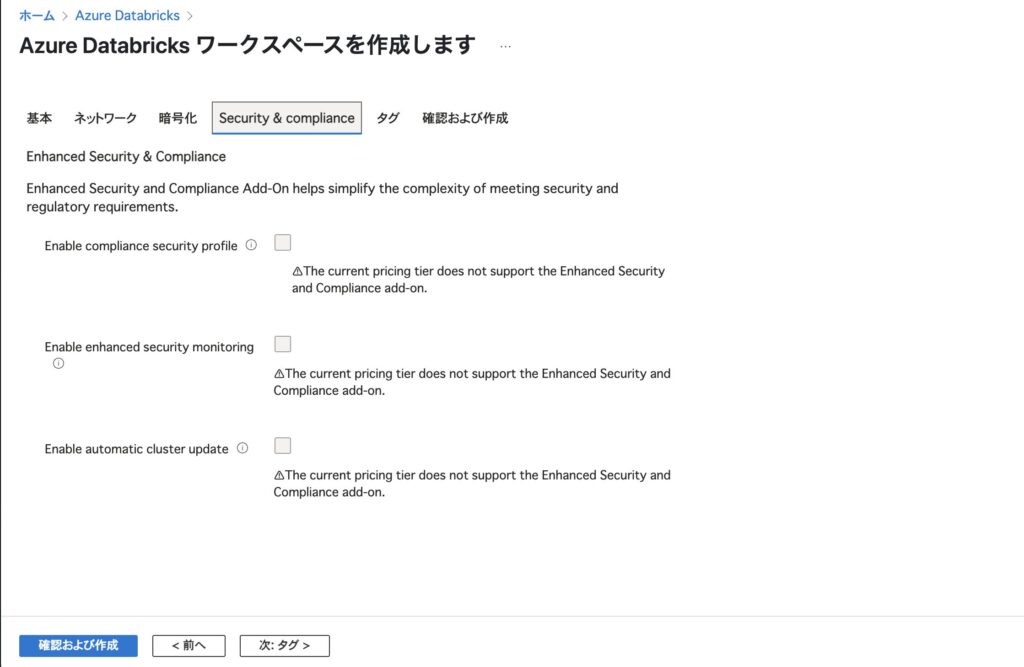
ステップ5:セキュリティ & コンプライアンス(任意)
こちらも Standard プランでは有効化できない項目が多いため、何も設定せずに「次へ」で進んでOKです。
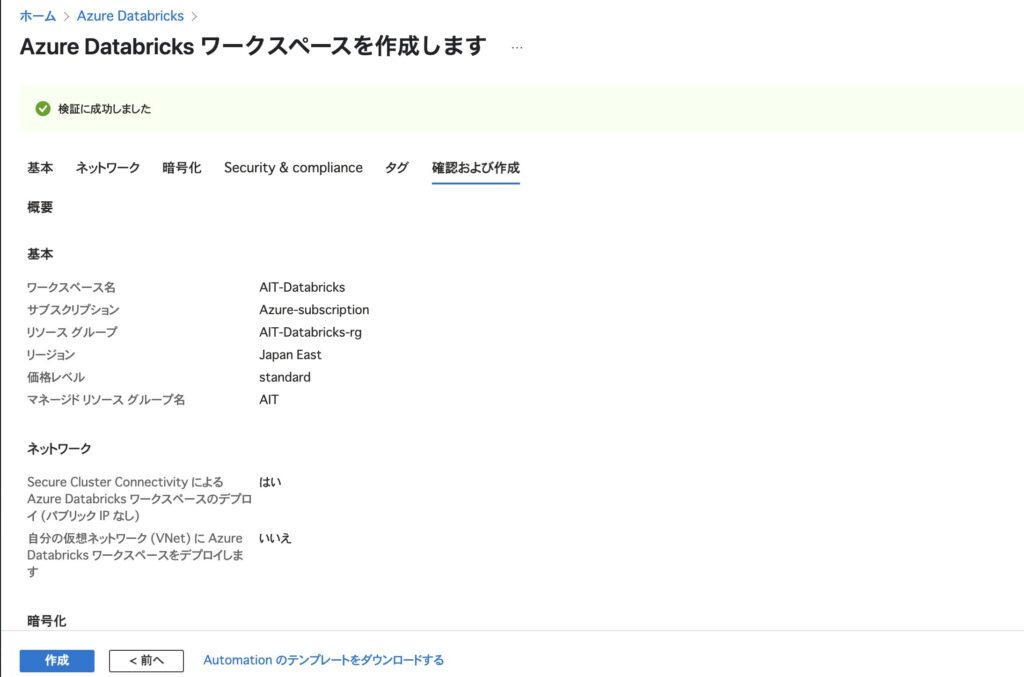
ステップ6:設定の確認と作成
最終確認画面が表示されます。すべての項目を確認したら、右下の 「作成」 ボタンをクリック。
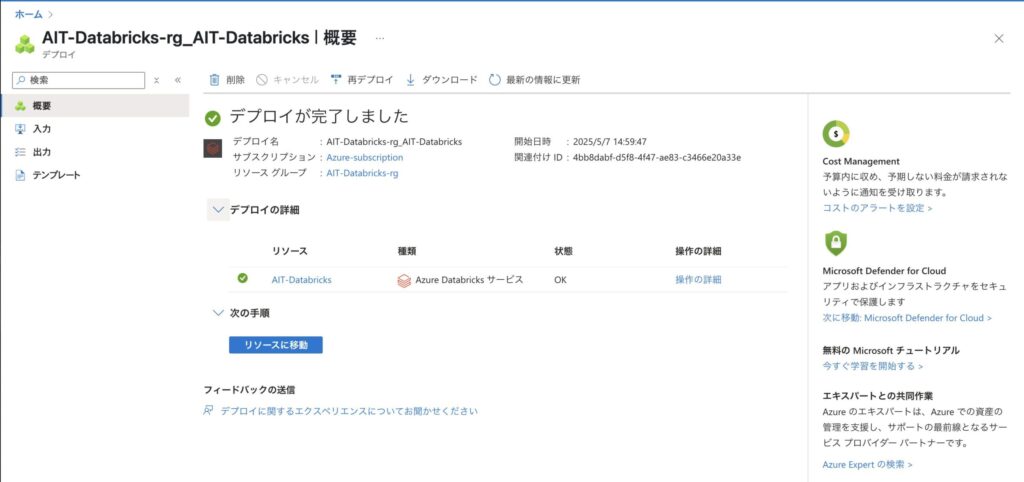
ステップ7:デプロイ完了の確認
数分後、「デプロイが完了しました」と表示されれば成功です。
リソース名「AIT-Databricks」が表示されていることを確認してください。
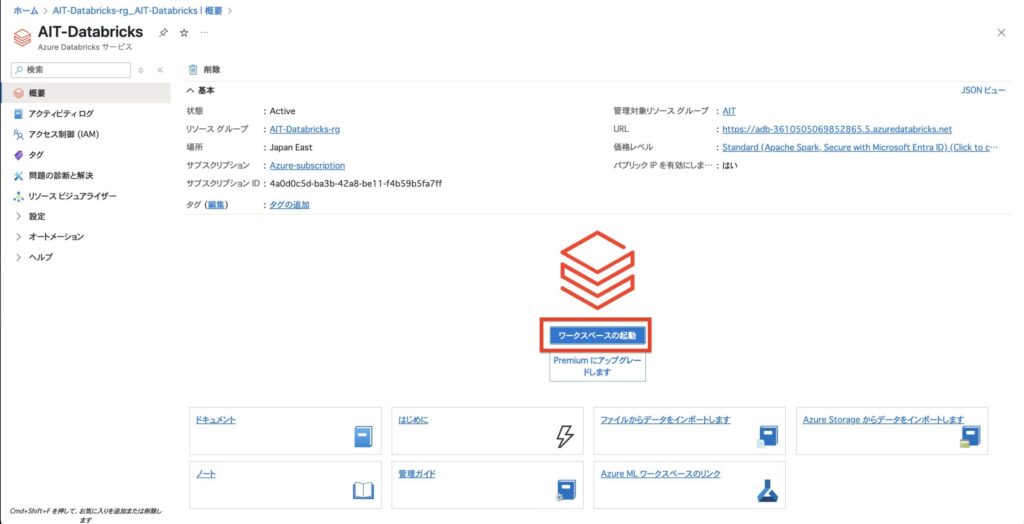
ステップ8:ワークスペースへ移動して起動
「リソースに移動」をクリックすると、ワークスペースの概要画面に遷移します。
ここから 「ワークスペースの起動」 をクリックすれば、Azure Databricks の使用が開始できます!
以上で、Azure Databricks ワークスペースの作成は完了です!
このワークスペースからノートブックを作成したり、データをインポートしたり、Apache Spark を使った分析が始められます。
まとめ
Azure Databricksは、初心者にも扱いやすいUIと強力な分散処理性能を兼ね備えたデータ分析・AIプラットフォームです。Azureサービスとの連携や機械学習への応用も容易で、効率的なデータ活用を実現します。初学者から中級者まで、活用の幅が広がるツールです。データエンジニアを目指す方、機械学習に挑戦したい方、Azure環境での分析業務に携わる方は、積極的に学習し、活用していきましょう。


コメント