
「画像をAIで解析する」と聞いて、どこか遠い未来の技術だと思っていませんか?
実は今、Microsoftの Azure Computer Vision を使えば、誰でも簡単に、画像や映像から“意味のある情報”を瞬時に抽出できる時代になっています。
たとえば、写真の中の文字を読み取ったり、写っている物体や人物を認識したり、さらには「この画像には何が写っているのか?」をAIが自動で説明してくれる――そんな機能がすぐに使えるのが、Azureの画像認識サービスです。
この記事では、Azure Computer Visionの凄さと、具体的な使い方・活用シーン・料金体系までを、初めての方にもわかりやすく解説していきます。これから画像認識を取り入れてみたい方は必見です!
Azure Computer Visionとは?
Azure Computer Visionは、Microsoft が提供するクラウドベースの画像解析サービスで、AIを活用して画像や動画の内容を自動的に認識・理解する機能をアプリケーションに簡単に組み込むことができます。いわば、「見る力」をアプリに与えるためのインフラです。
このサービスの中核となるのは、コンピュータビジョンと深層学習の技術です。Azure のバックエンドでは、大規模なニューラルネットワークモデルが稼働しており、画像から物体や文字、人物、空間情報などをリアルタイムで抽出し、構造化されたデータとして返してくれます。これにより、従来人間の目や手によって行っていた画像の判別・処理作業を、効率的かつ自動的に代替することが可能になります。
Azure Computer Visionの料金!無料プランはある?
Microsoft Azure の Computer Vision は、画像や動画をAIで解析できる便利なサービスですが、「実際に使うといくらかかるの?」という疑問を持つ方も多いです。
ここでは、Azure公式の価格表をもとに、料金体系を分かりやすく紹介します。
最新の価格情報や詳細については、Azure公式ページをご確認ください。
| ユースケース | おすすめプラン | 月額コスト目安 |
|---|---|---|
| お試し・学習目的 | Free F0 | 無料(最大5,000回まで) |
| 中小規模の運用 | Standard S1 | 数百円〜数千円/月 |
| 大規模・商用利用 | コミットメント or コンテナ | 数十万円/月〜 |
無料プラン(Free F0)
Azure Computer Visionには無料プラン(F0)が用意されており、以下の条件で利用可能です。
- 1か月あたり最大5,000回のトランザクション(画像解析の呼び出し)まで
- OCR・タグ付け・キャプション生成などの基本機能が対象
- 商用利用は不可、テストや学習用途限定
開発初期や社内PoC(概念実証)に最適なプランです。
有料プラン(Standard:S1)の料金
無料枠を超えて本格的に運用する場合は、有料プラン(Standard – S1)に移行する必要があります。料金は以下のように機能ごとに異なります(単位:1,000回あたりの価格、税込):
画像解析(Image Analysis)
- タグ付け:¥142.856 / 1,000回
- キャプション生成(簡易):¥92.856
- オブジェクト検出:¥142.856
- スマート切り抜き:¥57.143
- 画像の詳細キャプション(高度):¥357.143
OCR(光学文字認識)
- 日本語などの言語に対応:¥214.283 / 1,000回
🧠 空間分析(Spatial Analysis)
- 料金は¥1.5429 / 分(1カメラあたり)
- 複数カメラでの同時処理にも対応
この機能は、人の出入りのカウントや滞在時間分析などに使われ、スマート店舗や施設管理に活用されています。
🎬 ビデオ解析(Video Analysis)
- イベントごとの課金:1イベントあたり ¥7.143
- フレーム単位での解析:1,000フレームごとに ¥35.714
📦 コミットメントプラン(事前購入で割引)
大規模な利用を見込んでいる場合は、「コミットメントレベル」プランで月額固定料金を支払うことで、1回あたりの単価を大幅に抑えることができます。
たとえば:
- 月間 5,000,000回まで:約¥171,426(税込)
- 月間 100,000,000回まで:約¥539,991(税込)
※このプランは商用システムに大量実装する場合におすすめです。
🔒 封筒型コンテナー(オンプレミス対応)
Azureのクラウドを使わずに、自社環境でComputer Vision機能を動かしたい場合は「切断されたコンテナー(オンプレミス向けライセンス)」が必要です。
- 年額料金は約 ¥1,851,040〜(契約に応じて変動)
Computer Visionでできること
Azure Computer Vision は、画像や動画からテキスト・物体・顔・空間情報などをAIが自動で解析し、アプリに活用できるようにするクラウドサービスです。
ビジョンスタジオ(Vision Studio)では、次の4つの主要カテゴリに分類されています。
| カテゴリ | できること | 主な用途 |
|---|---|---|
| 光学文字認識 | 画像内の文字をテキスト化 | 書類デジタル化、翻訳 |
| 空間分析 | 人の動き・密度の検出 | スマート施設、混雑分析 |
| 顔 | 顔の検出・感情・認証 | セキュリティ、属性分析 |
| 画像解析 | 物体検出・キャプション生成 | 自動整理、視覚支援 |
1. 光学文字認識(OCR)
光学文字認識、通称OCR(Optical Character Recognition)は、画像やPDFなどの中に含まれている文字情報を読み取り、機械で扱えるテキストデータに変換する技術です。Azure Computer Vision のOCR機能を使えば、スキャンした文書や写真の中にある印刷文字や手書き文字を、簡単にデジタルデータとして抽出することができます。
特に便利なのは、スマートフォンで撮った領収書や看板、メモ帳の走り書きなど、さまざまな形式の画像に対応している点です。文字の位置や言語を自動で判別し、多言語にも対応しているため、日本語や英語、その他の言語が混在した文書でも正確に読み取ることが可能です。
主な機能
- 印刷・手書き文字の読み取り
- 多言語対応(日本語もOK)
- JSON形式でテキスト出力可能
活用例
- 請求書・領収書の自動読み取り
- 紙資料の電子化
- 翻訳・検索アプリ
2. 空間分析(Spatial Analysis)
空間分析(Spatial Analysis)は、Azure Computer Visionが提供する機能の中でも、現実空間の中で“人の動きや存在”をAIでリアルタイムに解析するための先進的な技術です。カメラの映像をもとに、そこに何人の人がいるのか、どこにどれくらいの時間滞在しているのかといった情報を自動で検出・追跡できます。
たとえば、小売店であれば「どの棚の前に人が集まりやすいか」「来店者はどのルートを歩いているか」などを視覚的に把握することが可能です。オフィスビルや公共施設では、入退室の自動カウントや混雑状況のリアルタイム監視としても活用されています。
主な機能
- 入退室カウント
- 特定エリアへの滞在検出
- 人の流れ・密度測定
活用例
- スマート店舗での来客分析
- オフィス・施設の混雑状況の可視化
- 安全管理(危険エリアへの侵入検知など)
3. 顔(Face)
顔認識機能は、Azure Computer Vision の中でも特に注目されている分野のひとつです。この機能では、画像や映像に映っている人の顔をAIが自動的に検出・分析し、必要に応じて個人を識別することも可能になります。
具体的には、まず画像内に存在する顔の位置を正確に特定し、次にその顔から得られる情報――たとえば年齢、性別、表情(感情)、眼鏡の有無などの特徴を推定します。また、複数の画像を比較することで、同一人物かどうかの判定(顔認証)も行えます。
主な機能
- 顔の位置検出
- 属性分析(年齢・感情・性別など)
- 顔認証(個人の識別)
活用例
- 顔認証による出退勤管理
- 顧客の属性分析(マーケティング活用)
- 入退室のセキュリティチェック
4. 画像解析(Image Analysis)
画像解析(Image Analysis)は、Azure Computer Vision が提供する機能の中で最も幅広く、画像全体の内容をAIが理解し、意味のある情報として返す技術です。人が写真を見て「これは猫だ」「海辺で遊んでいる人たちだ」と瞬時に認識できるように、AIが画像を“理解する”力を与えてくれるのがこの機能です。
この機能では、画像に写っている物体やシーンを自動的にタグ付けしたり、「2人の子どもが公園で遊んでいる」といったキャプション(説明文)を生成したりすることができます。また、画像内に含まれる物体の検出とその位置情報の取得も可能です。たとえば、人物、動物、食べ物、乗り物など、日常的に登場する多様なカテゴリを識別できます。
さらに、画像の中に顔があるかどうかを検出したり、色の構成、成人向けコンテンツかどうかの判定なども行えるため、コンテンツの自動フィルタリングやメディア管理において非常に有効です。
主な機能
- 自動タグ付け(例:動物・建物・自然など)
- キャプション生成(例:「3人が海辺で遊んでいる」)
- 一般的な物体検出(人物、車、食べ物など)
活用例
- SNSや画像管理アプリでの自動分類
- 障がい者向けの視覚サポートアプリ
- 監視映像の異常検出支援
Azure Computer VisionとCustom Visionの違いとは?
Azureが提供する2つの画像認識サービス「Computer Vision」と「Custom Vision」の違いを、ユースケースに沿ってわかりやすく紹介します。
| 項目 | Azure Computer Vision | Azure Custom Vision |
|---|---|---|
| 学習の有無 | 不要(すぐ使える) | 必要(自分で画像を用意) |
| 用途 | 汎用的な画像解析 | 特定の分類・検出 |
| 操作性 | API中心 | Web UIあり、操作も直感的 |
| 導入の難易度 | 低(非エンジニアでもOK) | 中(画像収集・ラベル付けが必要) |
| オフライン対応 | × | ○(エッジデバイスへのデプロイが可能) |
Azure Computer Visionはすぐ使える“汎用AIモデル”
Azure Computer Vision は、Microsoft が事前に学習させた汎用的な画像解析モデルをAPI経由で使えるサービスです。専門知識や機械学習の経験がなくても、画像を送信するだけでテキスト、ラベル、物体の位置、キャプション(説明文)などが返ってきます。
たとえば以下のようなことができます:
- 写真から文字を読み取る(OCR)
- 画像に写っているものを自動でタグ付け
- 人の顔の位置を検出
- 「2人の子どもが公園で遊んでいる」などのキャプション生成
特徴:学習不要ですぐ使える
向いている人:まず画像解析を試してみたい人、汎用の処理で十分な人
Azure Custom Vision:自分専用のAIを育てるツール
一方の Custom Vision は、ユーザー自身が画像をアップロードし、「この画像はA」「こっちはB」というようにラベル付けして学習させるカスタムモデル構築サービスです。
たとえば自社製品の型番を識別したい、工場で不良品だけを検出したいといったニッチで特殊な分類には、汎用モデルでは精度が出ません。そんなときに活躍するのが Custom Vision。
少量の画像(50枚〜)でも学習可能で、Web UI 上でトレーニングからテストまで完結。さらに、学習したモデルはクラウドAPIとして呼び出せるだけでなく、モバイルやエッジ端末用にエクスポートしてオフラインで使うことも可能です。
特徴:特定用途に高精度で対応できる
向いている人:独自の画像分類が必要な開発者、業務システムでAI活用したい企業
Azure Computer Visionの使い方(OCR手順)
最近では、画像からテキストを抽出する「OCR(光学文字認識)」技術が多くのアプリや業務に活用されています。ここでは、Microsoft の提供する Azure AI Vision Studio を使って、誰でも簡単に画像から文字を読み取る方法をご紹介します。
Computer Vision リソースの作成
まずは、Azureのアカウントが必要です。まだ持っていない場合は、公式サイトから無料で登録できます。
次に、「Computer Vision」のリソースを作成しましょう。すでにリソースを作成済みの場合は、Vision Studioにログインします。
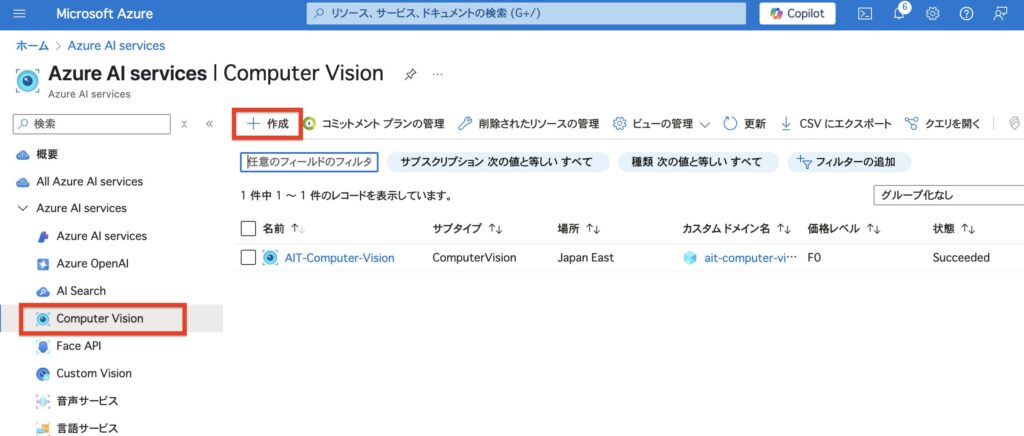
必要最小限の5つの項目だけを入力し、他はすべて既定値のままで構いません。
| 項目名 | 設定内容 |
|---|---|
| サブスクリプション | 使用するAzureのサブスクリプションを選択 |
| リソースグループ | 既存のものを選択、または「新規作成」で任意の名前を設定(例:my-vision-rg) |
| リージョン | 使用地域を選択(例:Japan East) |
| 名前 | リソース名を入力(例:AIT-Computer-Vision) |
| 価格レベル(Pricing Tier) | F0(無料枠)を選択してテスト用に設定 |
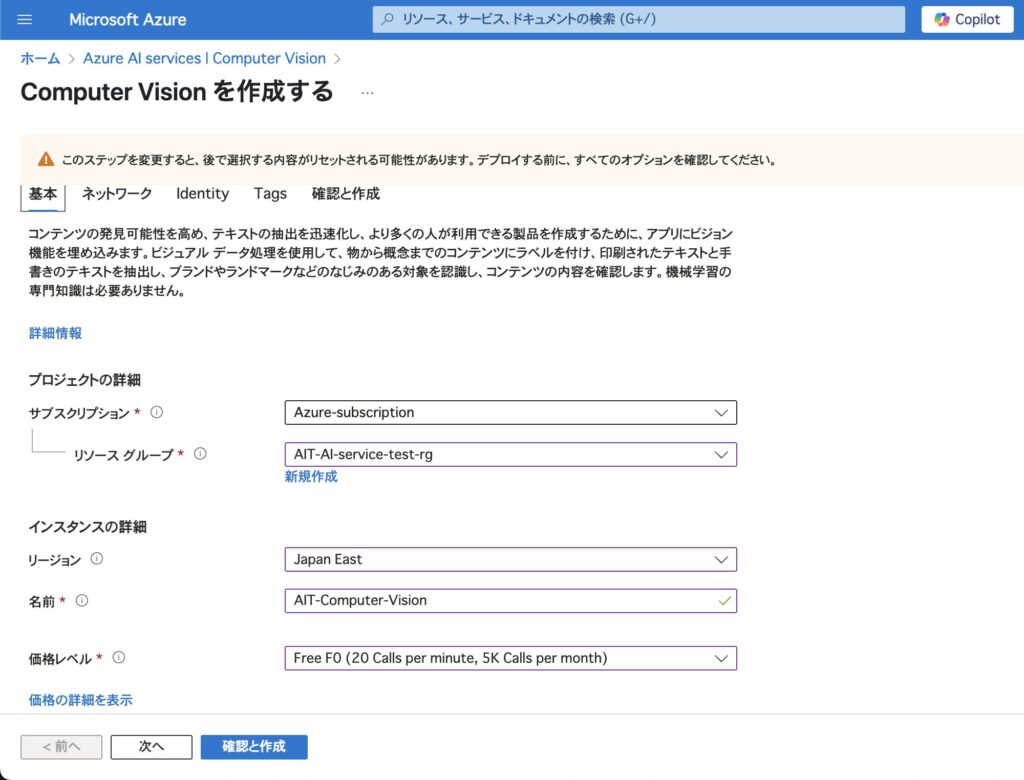
リソース作成時には、以下の「責任あるAI通知」が表示されます。内容を確認のうえ、チェックボックスに✅を入れて次に進みましょう。

この内容に同意できる場合は、チェックボックスをオンにしてください。
責任あるAI通知
Microsoft は、この Azure AI サービスの適切な運用に関する技術文書を提供しています。このサービスを利用するお客様は、この文書を確認し、それに従ってサービスを使用することを認識し、同意するものとします。
この Azure AI サービスは、(製品ドキュメントにさらに詳しく記載されている場合がある)バイオメトリクス データを含むカスタマー データを処理することを目的としており、お客様が個人識別やその他の目的で使用する独自のシステムに組み込むことができるものです。
お客様は、オンライン サービス データ保護契約(Online Services DPA)に含まれるバイオメトリクス データに関する義務を遵守する責任があることを認識し、同意するものとします。
「確認および作成(Review + create)」をクリック。
検証が完了したら「作成(Create)」ボタンを押します。
数十秒後、リソースの作成が完了し、すぐに利用できるようになります。
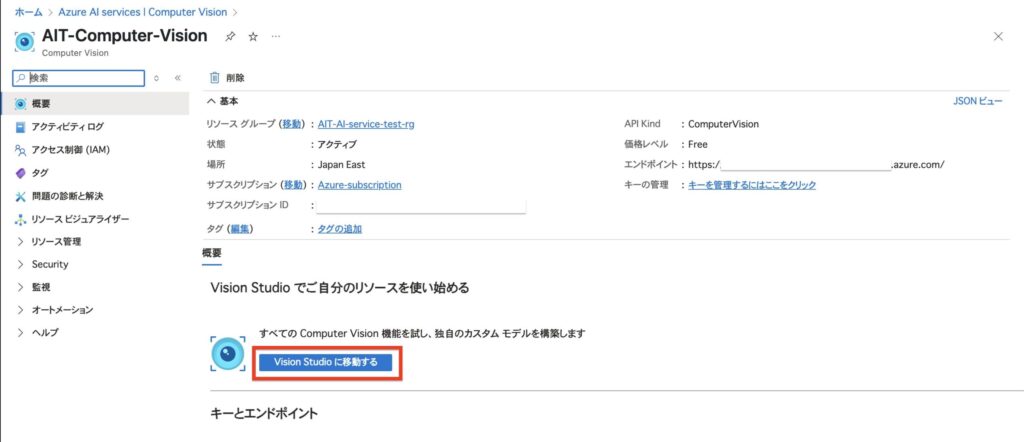
1.Vision Studioに移動する
リソースの準備ができたら、ブラウザでVision Studioにアクセスしましょう。
Vision Studioは、Azureが提供するノーコードのビジュアルツールで、Computer Visionを簡単に試すことができます。
画像のように、Computer Visionページを開き「Vision Studioに移動する」をクリックすることでアクセス可能です。
2. OCR(文字認識)の機能に進む
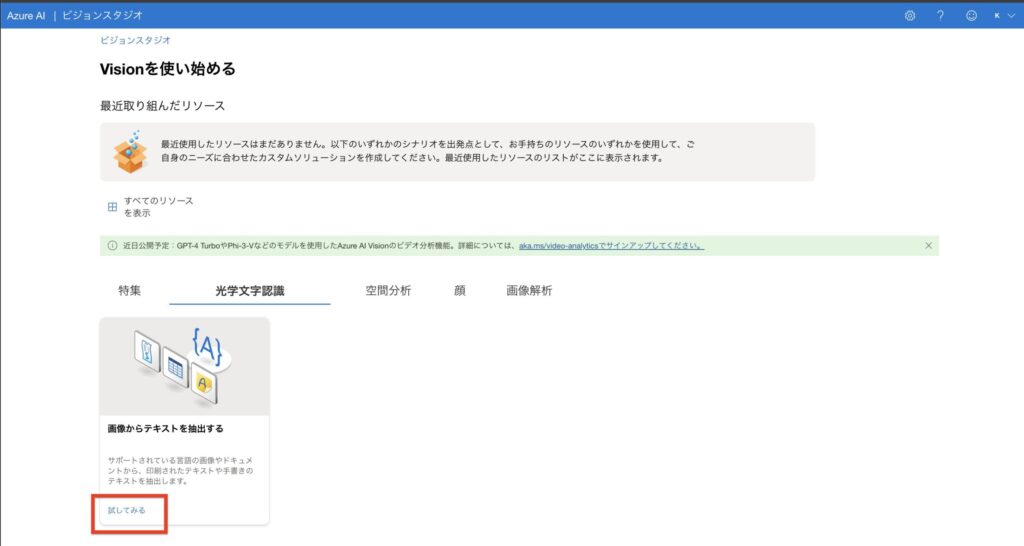
Vision Studioにアクセスすると、「Get started with Vision(Visionをはじめよう)」というトップページが表示されます。
画面中央には「Featured(注目)」「Optical character recognition(光学文字認識)」「Spatial analysis(空間分析)」などのカテゴリタブが並んでいます。ここで使いたい機能を選んで進みます。
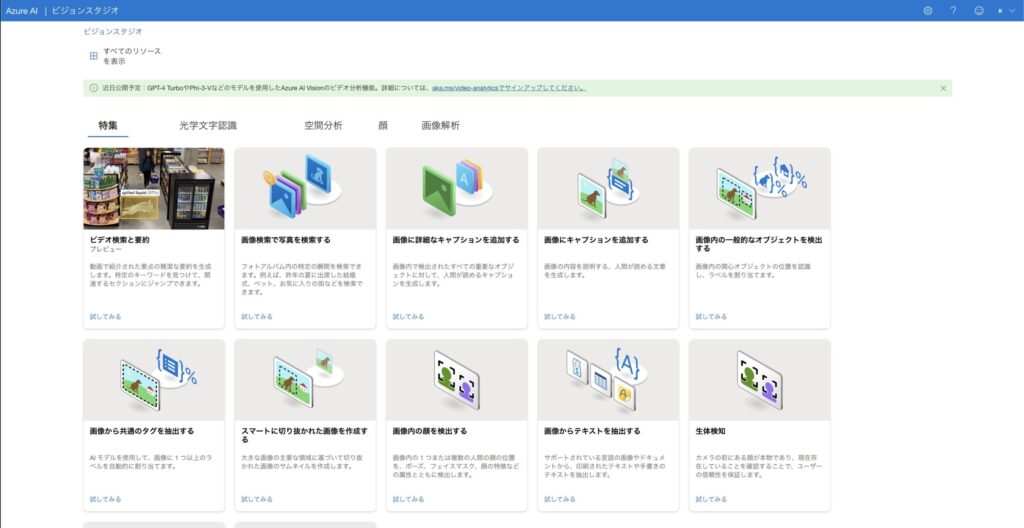
OCR機能を使いたい場合は、「Optical character recognition」タブ内の「「画像からテキストを抽出」(英語の場合:Extract text from images)」をクリックしましょう。
3. 画像を選ぶ
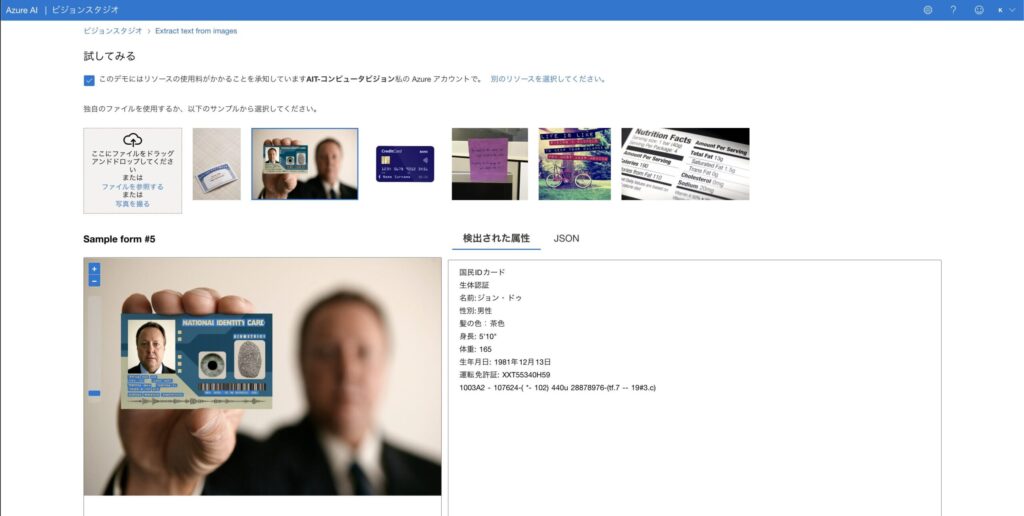
OCRツールを開くと、「画像からテキストを抽出する」という画面が表示されます。ここで、解析したい画像をアップロードして、実際にどのようにテキストが読み取られるか確認できます。
画像のアップロード方法は2つ
- 自分のファイルをアップロードする(ドラッグ&ドロップ またはファイル選択)
- サンプル画像を選ぶ(画面上部に用意された6種類の画像から選択可能)
画面左側で画像を選択すると、右側のパネルに「検出された属性」として、抽出されたテキスト結果が即座に表示されます。また、JSON形式でも結果を確認できるので、開発者の方にも便利です。
4. 使用料の注意
Vision Studioは無料で試せる範囲もありますが、本番環境で使う際はAzureの従量課金が発生します。
特にOCRのような処理では、リクエスト回数に応じた課金が行われます。無料枠(F0)を利用できる場合もあるので、以下のポイントに注意しましょう
- 大量に使う場合はコスト試算をしておくのがベター
- 毎月の無料利用枠:F0価格帯では月5,000トランザクションまで無料
- それを超えると有料プラン(S1など)に自動切替
まとめ
Azure Computer Vision は、従来であれば高度な画像処理アルゴリズムやGPU環境が必要だったタスクを、クラウドAPI一つでスケーラブルかつ高精度に実現できる強力なサービスです。OCR、物体検出、顔認識、画像キャプション生成といった処理が、SDKやREST APIを通じて容易に組み込めるため、PoCから本番環境への展開もスムーズです。
また、柔軟な料金体系やコンテナ対応により、クラウドネイティブなアーキテクチャはもちろん、オンプレミス環境やエッジデバイスへの展開も視野に入れた設計が可能です。
今後ますます需要が高まる画像認識技術。その中でも Azure Computer Vision は、信頼性・拡張性・実用性を兼ね備えた選択肢として、非常に魅力的な存在と言えるでしょう。

